
Routing with Lines through Polygons
One of my favorite layers to route with pgRouting is the water layer. I am interested in where water comes from, where it goes, where runoff happens, and how urban development interacts with this powerful force of nature. The OpenStreetMap water layer, however, presents a challenge when routing with PostGIS and pgRouting: Polygons.
Why are polygons a challenge? A routing network using pgRouting is built from lines (edges). Now, to state the obvious: polygons are not lines.
Real world waterway networks are made up of both lines and polygons. Rivers, streams, and drainage routes are predominately (but not exclusively!) mapped using lines. These lines feed into and out of ponds, lakes, and reservoirs. The following animation shows how much impact the water polygons can have on a waterway network... some very important paths simply disappear when they are excluded.
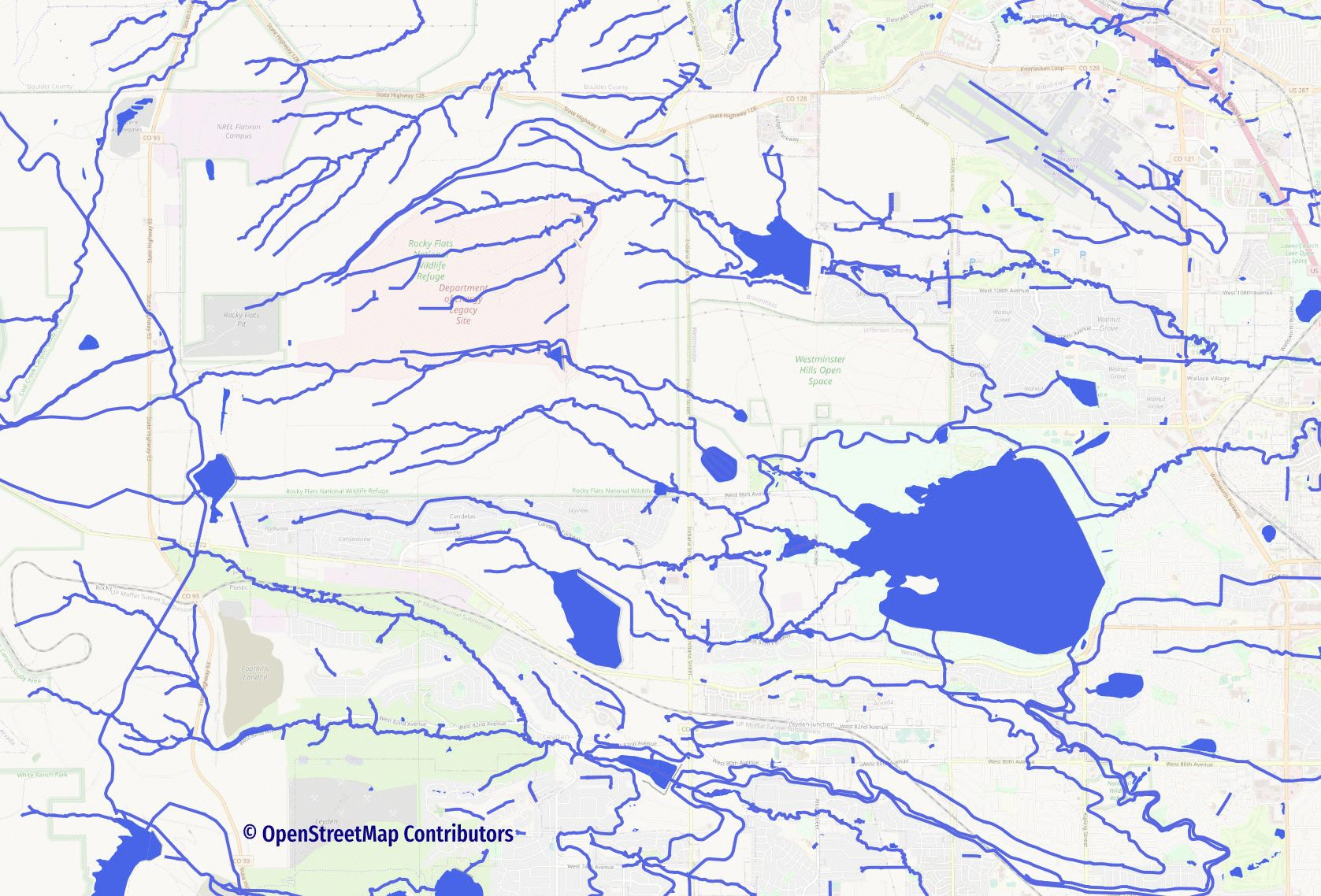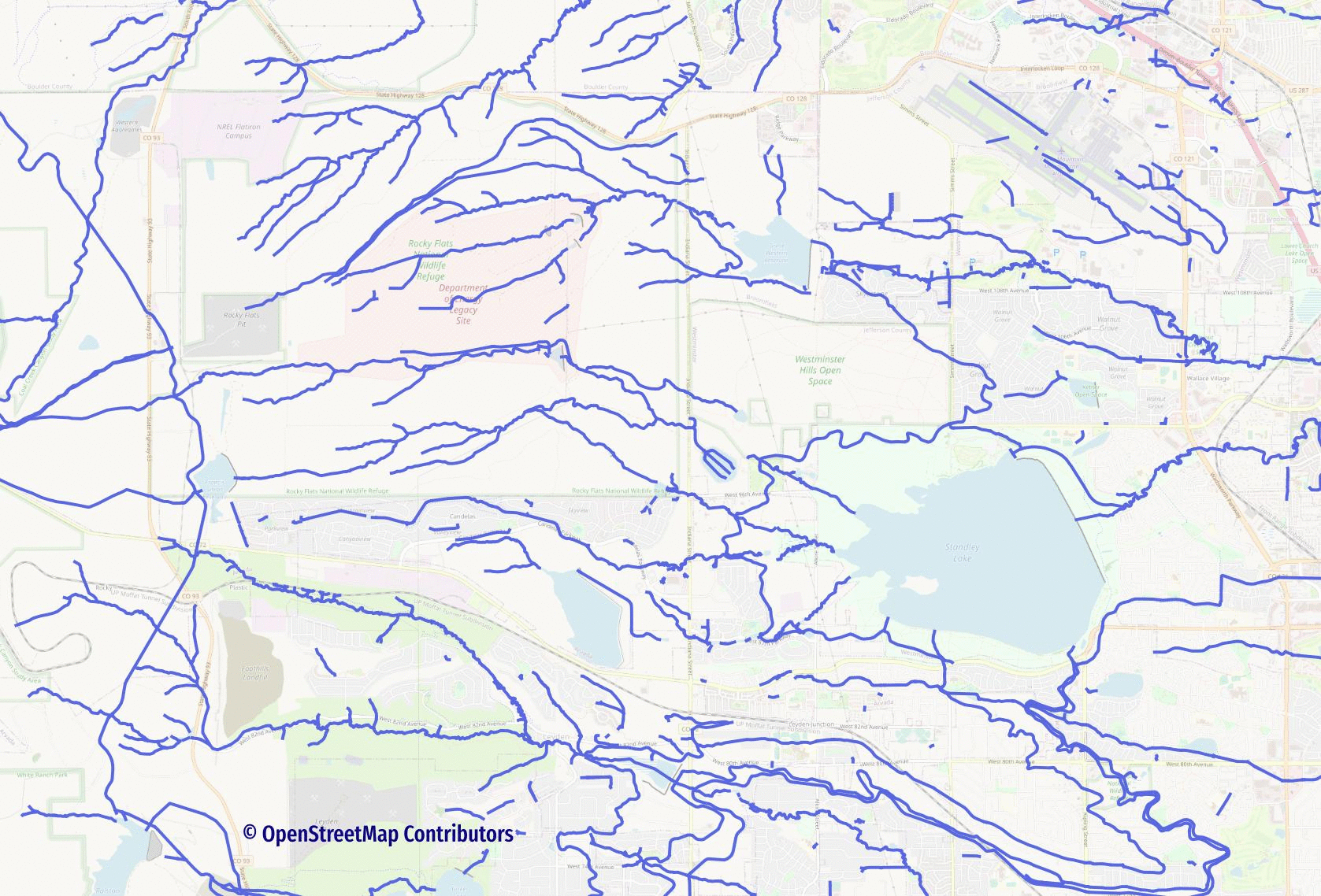
To make the full water network route-able we need to create a combined line layer. The combined line layer will include:
- Initial
osm.water_lineinputs - Medial axis lines from
osm.water_polygon - Lines to connect initial inputs to medial axis
Postgres 15 Configuration Changes
A few years ago around the time PostgreSQL 12 was released, I
created a tool to help
identify the changes to postgresql.conf. The pgConfig tool has helped me become
(and stay) aware of important changes to Postgres configuration as I work with
various major version upgrades.
Now that Postgres 15
is available,
pgConfig is updated
with the latest
configuration.
This post provides a quick look at changes in the Postgres 15
version of the postgresql.conf options.
Summary of changes
The postgresql.conf for Postgres 15 has 6 new items,
3 changed items and 1 removed item. Visit the
pgConfig site
to see the full list of changes.

Better OpenStreetMap data using PgOSM Flex 0.6.0
In late 2020 when osm2pgsql released the flex output I eagerly jumped on that bandwagon. The osm2pgsql flex output enabled the type of data structure and cleanup abilities I had always wanted from osm2pgsql. By January 2021 the PgOSM Flex project was up and running and I was phasing out my legacy OpenStreetMap processes. Since then, I have written more than a dozen posts exploring different improvements and use cases for the OpenStreetMap data loaded via PgOSM Flex. This post looks at a few notable improvements to version 0.6.0 over prior versions. The two areas of focus are:
- Data quality
- Usability
Data quality improvements
The set of improvements that gave me the idea for this post were made
in PgOSM Flex versions 0.5.1 and 0.6.0.
Version 0.5.1
took advantage of the long awaited addition of multilinestring support
to osm2pgsql. Adding that feature in osm2pgsql allowed relations of lines to
be added in the same manner that
relations of polygons
had used. Without the multilinestring support, relations such as
13642053,
shown in the following screenshot, were being skipped by the PgOSM Flex import.
This improvement targeted roads, waterways, and public transport layers.
Book Release! Mastering PostGIS and OpenStreetMap
I'm excited to announce my book, Mastering PostGIS and OpenStreetMap, is available to purchase as of October 1, 2022! This book provides a practical guide to introduce readers to PostGIS, OpenStreetMap data, and spatial querying. Queries used for examples are written against real OpenStreetMap data (included) to help you learn how to navigate and explore complex spatial data. The examples start simple and quickly progress through a variety of clever spatial queries and powerful techniques.
Section 12.3, Create Denver specific tables, is available as a free preview section. The full Table of Contents is available from the free preview page.
Who is this book for?
Mastering PostGIS and OpenStreetMap is for anyone that wants to learn more about PostGIS and/or OpenStreetMap data. The hefty Appendix helps keep new users on track without distracting users with more experience. The following table gives an idea of the topics covered.
| Topic | Included? |
|---|---|
| Install PostGIS | ✅ |
| Spatial SQL queries | ✅ |
| Basics of OpenStreetMap tagging | ✅ |
| Load OpenStreetMap data to PostGIS | ✅ |
| Find and use local SRIDs everywhere | ✅ |
| Handle real-world (dirty!) data | ✅ |
| Performance of Geometry vs. Geography | ✅ |
| Routing | ✅ |
Postgres 15 improves UNIQUE and NULL
Postgres 15 beta 2 was released
recently! I enjoy Beta season... reviewing and testing new features
is a fun diversion from daily tasks. This post takes a look at an improvement
to UNIQUE constraints on columns with NULL values. While the nuances of unique constraints are not as flashy
as making sorts faster (that's exciting!),
improving the database developer's control over data quality is always a good benefit.
This email chain has the history behind this change. The Postgres 15 release notes summarize this improvement:
"Allow unique constraints and indexes to treat NULL values as not distinct (Peter Eisentraut)
Previously
NULLvalues were always indexed as distinct values, but this can now be changed by creating constraints and indexes usingUNIQUE NULLS NOT DISTINCT."
Two styles of UNIQUE
To take a look at what this change does, we create two tables.
The null_old_style table has a 2-column UNIQUE constraint
on (val1, val2). The val2 allows NULL values.
CREATE TABLE null_old_style
(
id BIGINT GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY,
val1 TEXT NOT NULL,
val2 TEXT NULL,
CONSTRAINT uq_val1_val2
UNIQUE (val1, val2)
);
 Mastodon
Mastodon