
Postgres 12 Generated Columns and PostGIS
One of the main new features in Postgres 12 I was excited for was generated columns. I mentioned this feature breifly in my intial reivew of Postgres 12 where I gave one example of how I have already used generated columns. The most likely and common use cases for generated columns work as expected and improve performance for SELECT queries.
This post dives further into the feature including a peek at performance as usage goes beyond "convenience" columns (concatenate strings, basic formulas, etc.) to "heavy compute" columns. I am interested in applying this feature to work on our PostGIS data and in those tests performance does not quite meet expectations... yet! I fully expect this is either my user error or something that can be resolved in a future release.
Test System
Tests were ran on a local VM with 4 CPU and 8 GB RAM on a 7200 RPM HDD. PostgreSQL 12.1 and PostGIS 3.0.
All queries were run a minimum of five (5) times with EXPLAIN (ANALYZE, COSTS, BUFFERS, VERBOSE, SETTINGS ON) and the results displayed are representation of the average execution time. The EXPLAIN line is not shown with the queries below.
The new
SETTINGS ONoption is great!
The osm_co.road_line table used in spatial joins has 687,457 rows. Exact queries used serve
limited (or zero) real-world purpose but do represent common real-world scenarios.
Generated column, simple calculation
Starting with a simple test on a BIGINT column, I created a generated column that performs
a random calculation. The calculation itself isn't important, just that it does something.
CREATE TABLE numbers
(
id INT GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY,
num BIGINT NOT NULL,
num_c1 BIGINT GENERATED ALWAYS AS (ceil(num * 3.14 / 42)) STORED
);
Add some data into the num column, the id and num_c1 columns will take care of
themselves.
INSERT INTO numbers (num)
SELECT generate_series(42, 420000);
On-the-fly performance
The first query sets the baseline by performing the calculation manually for each column. In this case we calculate the average, minimum and maximum values.
SELECT AVG(ceil(num * 3.14 / 42)),
MIN(ceil(num * 3.14 / 42)),
MAX(ceil(num * 3.14 / 42))
FROM numbers;
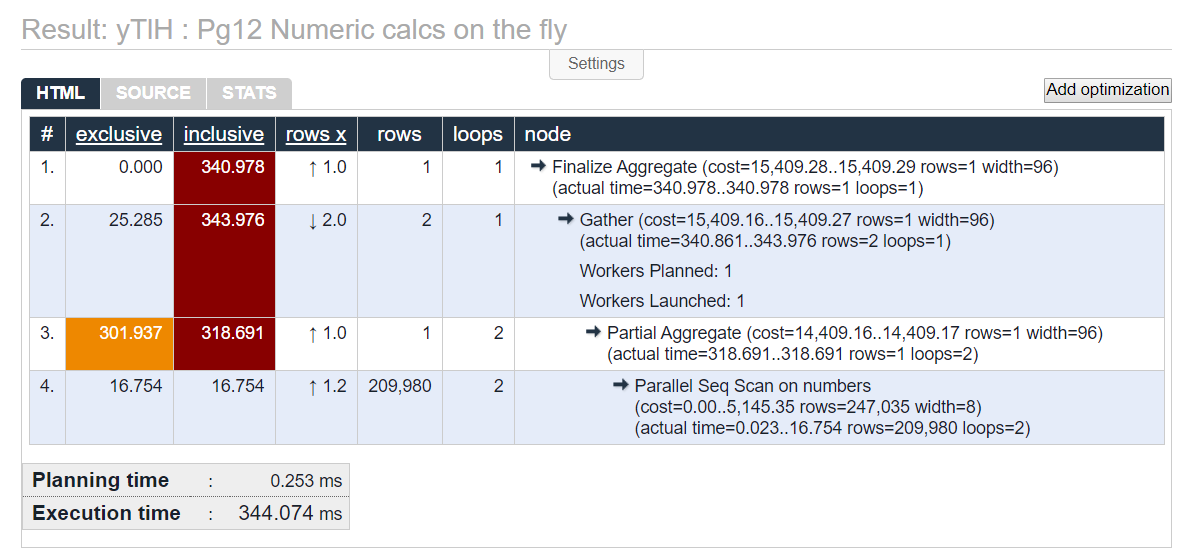
See full EXPLAIN results at https://explain.depesz.com/s/yTlH.
Generated column performance
Now using the generated column to provide the same three aggregations. This version using the generated column returns 83% faster than running the calculation multiple times on the fly. Faster is the expected result!
SELECT AVG(num_c1), MIN(num_c1), MAX(num_c1 * 12)
FROM numbers
;
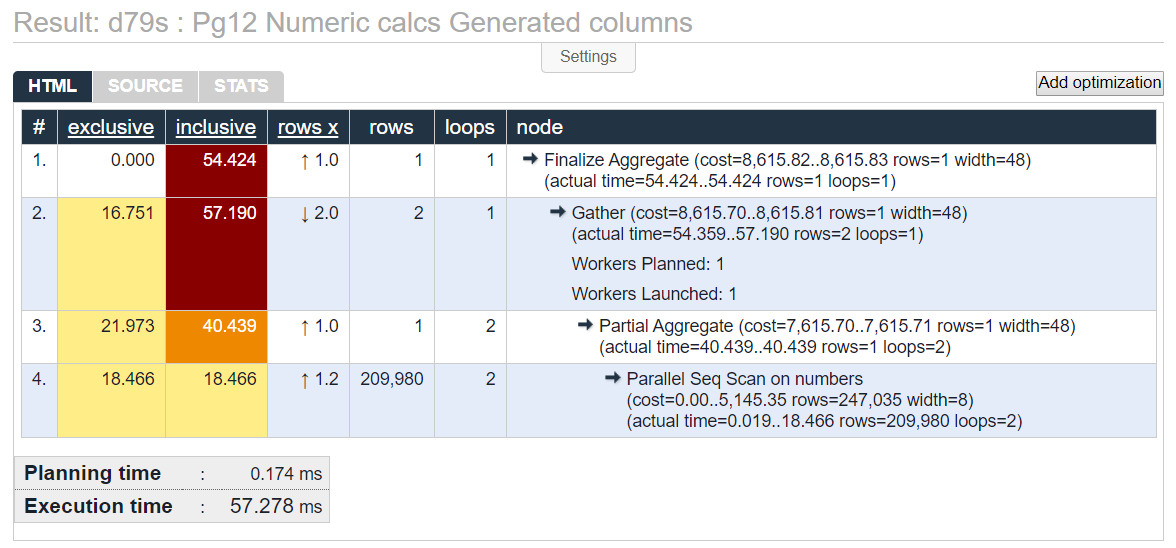
See full EXPLAIN results at https://explain.depesz.com/s/d79s.
PostGIS and generated columns
The queries used in this section use a PostGIS database loaded with Colorado OpenStreetMap
data via our PgOSM project.
This data set uses the default SRID (from osm2pgsql) of 3857, this is handy because it renders
by default in DBeaver and
PgAdmin 4 among other software. Also, the units
is in meters so makes functions like ST_DWithin() easy to use.
It is a common task to bring in another table of spatial data (from a client or vendor), often in a different SRID
than your data. The following example creates a table of random points within the polygon of the Colorado state boundary using ST_GeneratePoints() to represent this external data source. The first portion of the CTE generates
the random points, the second part builds the id column and transforms the points to 4326
in the new column way_4326.
CREATE TABLE osm_co.random_points AS
WITH a AS (
SELECT (ST_Dump(ST_GeneratePoints(way, 20000))).geom
FROM osm_co.boundary_polygon bp
WHERE name = 'Colorado'
)
SELECT ROW_NUMBER() OVER (ORDER BY geom) AS id,
ST_Transform(geom, 4326) AS way_4326
FROM a
;
Create a primary key on the table and add a GIST index.
ALTER TABLE osm_co.random_points
ADD CONSTRAINT PK_random_points
PRIMARY KEY (id);
CREATE INDEX gix_random_points_way_4326
ON osm_co.random_points USING GIST (way_4326);
Transform and Buffer on the fly
We want to use this layer with our other spatial layers so we need to use
ST_Transform(way_4326, 3857) to re-project the data to match.
We can do this on the fly as we did with the numeric calculations above.
The following query does the transform, creates a buffer 500m around each point,
and then joins to the roads within the buffer.
One of the downside of doing this type of thing all inline is the code starts getting verbose, with more and more numbers, commas and parens required typos are harder to detect. This example is quite simplistic and queries in the wild can get... gnarly.
SELECT COUNT(p.*)
FROM osm_co.random_points p
INNER JOIN osm_co.road_line r
ON ST_Contains(ST_Buffer(ST_Transform(way_4326, 3857), 500), r.way)
;
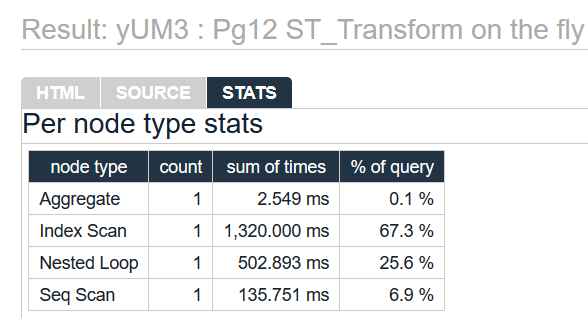
See full EXPLAIN results at https://explain.depesz.com/s/yUM3
We can see this isn't a super fast query, taking nearly 2 seconds. The data we're working with for these examples isn't terribly large. As the data grows, this will slow down quickly.
Transform and Buffer, generated
By using a generated column we can put the complex bits into a buffered column with a GIST index. It feels "right" to create a column to do this, much like I would in a view. It'd be nice to get that boost in execution speed when using the data too.
ALTER TABLE osm_co.random_points
ADD way_buffer GEOMETRY (POLYGON, 3857)
GENERATED ALWAYS AS (ST_Buffer(ST_Transform(way_4326, 3857), 500)) STORED
;
CREATE INDEX gix_random_points_way_buffer ON osm_co.random_points
USING GIST (way_buffer);
The query returns the same count (16,623 records), but unfortunately it takes 157% longer! Now returning in just over 5 seconds. Not what I was expecting.
SELECT COUNT(p.*)
FROM osm_co.random_points p
INNER JOIN osm_co.road_line r
ON ST_Contains(p.way_buffer, r.way)
;
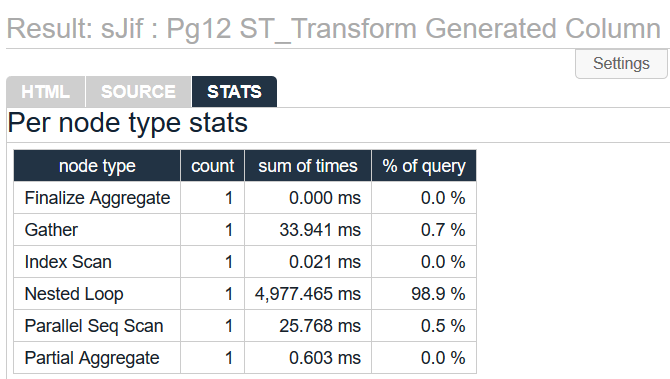
See full EXPLAIN results at https://explain.depesz.com/s/sJif.
Update 9/6/2020: It seems there is a bug in PostGIS causing this issue. Regina Obe submitted this ticket about the issue. From the notes on the issue so far, it seems the performance issue resolves itself over time. I will try to monitor the status of that issue and update this post accordingly.
Different execution plans
Both queries use JIT (enabled by default in Pg12). The first query (on the fly) reports 10 functions.
JIT:
Functions: 10
The second query (generated column) reports 32 functions.
JIT:
Functions: 32
It took a while for me to realize that in the first query we are performing operations on
POINT data. The second query is using POLYGON data. While the end result of the queries are identical, (and the first queries does create polygons on the fly!), what the query planner sees is completely different in the two queries, hence very different execution plans.
The second plan uses parallel query too. Regardless that this particular query is running slower I am happy to see PostGIS queries using parallel more in Pg 12!
-> Gather (cost=143439909.55..143439909.76 rows=2 width=8) (actual time=5031.719..5037.798 rows=3 loops=1)
Output: (PARTIAL count(p.*))
Workers Planned: 2
Workers Launched: 2
Check manual POLYGON table
I have every reason to think the persisted polygon layer should be faster than the calculations from points, so to double check I'll create a normal column and set the pre-calculated buffer to the new column. This is a trick I have used in the past when I didn't want to use a view (materialized or regular).
ALTER TABLE osm_co.random_points
ADD way_buffer_manual GEOMETRY (POLYGON, 3857)
;
UPDATE osm_co.random_points
SET way_buffer_manual = way_buffer
;
CREATE INDEX gix_random_points_way_buffer_manual ON osm_co.random_points
USING GIST (way_buffer_manual);
This query, as expected, ran much faster than the original on-the-fly calculation based on the original points. Still using parallel query, good! This was the performance I was hoping for from the generated column, but something isn't quite there for this particular data.
SELECT COUNT(p.*)
FROM osm_co.random_points p
INNER JOIN osm_co.road_line r
ON ST_Contains(p.way_buffer_manual, r.way)
;
See full EXPLAIN results at https://explain.depesz.com/s/Z7J
Other dials I adjusted
Throughout the course of writing this post I tried a number of different approaches with
PostGIS-related data. I tried simpler examples, more complex examples, different data,
different queries and kept coming up with similar sorts of results. I adjusted
max_parallel_workers_per_gather and toggled jit and results were consistent.
My first hunch is was that it could be due to the data being stored in
TOAST, if that is was the case it would have affected other data stored in large objects.
Update: Not TOAST related
Update 12/13/2019 -- When I work with data in PostGIS I often assume the data is put into TOAST, knowing that is not always the case. Turns out the table I used above, with one point and two polygon tables still wasn't even close to going into TOAST. A quick look showed no data spilled into TOAST, the average size per row (with 3 buffers!) is only 2 kB / row.
Name |Value |
-------------|-------------|
s_name |osm_co |
t_name |random_points|
bytes_per_row|2050.4576 |
Summary
Generated columns are working great for the numeric and text data I have tested so far. The functionality technically is there for using PostGIS functions but something is getting in the way of performance. I will continue investigating this and update this post as necessary.
Overall I am very happy with generated columns in Postgres 12 and look forward to continued improvements!
Need help with your PostgreSQL servers or databases? Contact us to start the conversation!
 Mastodon
Mastodon