
Better OpenStreetMap data using PgOSM Flex 0.6.0
In late 2020 when osm2pgsql released the flex output I eagerly jumped on that bandwagon. The osm2pgsql flex output enabled the type of data structure and cleanup abilities I had always wanted from osm2pgsql. By January 2021 the PgOSM Flex project was up and running and I was phasing out my legacy OpenStreetMap processes. Since then, I have written more than a dozen posts exploring different improvements and use cases for the OpenStreetMap data loaded via PgOSM Flex. This post looks at a few notable improvements to version 0.6.0 over prior versions. The two areas of focus are:
- Data quality
- Usability
Data quality improvements
The set of improvements that gave me the idea for this post were made
in PgOSM Flex versions 0.5.1 and 0.6.0.
Version 0.5.1
took advantage of the long awaited addition of multilinestring support
to osm2pgsql. Adding that feature in osm2pgsql allowed relations of lines to
be added in the same manner that
relations of polygons
had used. Without the multilinestring support, relations such as
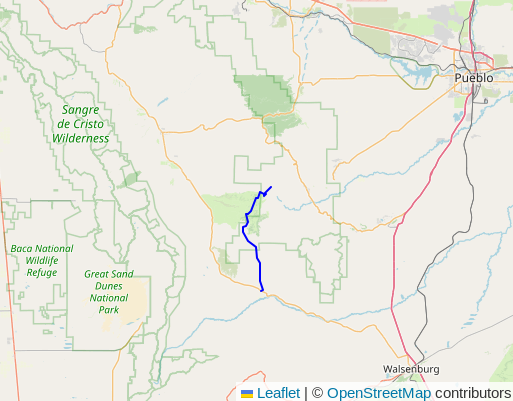
13642053,
shown in the following screenshot, were being skipped by the PgOSM Flex import.
This improvement targeted roads, waterways, and public transport layers.
While I was making the changes to add the multilinestring support I
realized I had not added relations to some other polygon layers. Those improvements
weren't blocked by anything other than I hadn't noticed this issue yet.
A rather prominent
example of missing data in PgOSM Flex's osm.water_polygon table was Dillon Reservoir.
The following query selects the data from a Colorado data set imported
using PgOSM Flex 0.5.0. We get one result for Old Dillon Reservoir, which is
a small reservoir next to what we know as Dillon Reservoir today.
SELECT osm_id, osm_type, osm_subtype, name,
ST_Area(ST_Transform(geom, 2773)) AS area_m,
geom
FROM osm_0_5_0.water_polygon
WHERE name ILIKE '%Dillon Reservoir%'
;
┌──────────┬──────────┬─────────────┬──────────────────────┬──────────┐
│ osm_id │ osm_type │ osm_subtype │ name │ area_m │
╞══════════╪══════════╪═════════════╪══════════════════════╪══════════╡
│ 39410606 │ natural │ water │ Old Dillon Reservoir │ 58278.22 │
└──────────┴──────────┴─────────────┴──────────────────────┴──────────┘
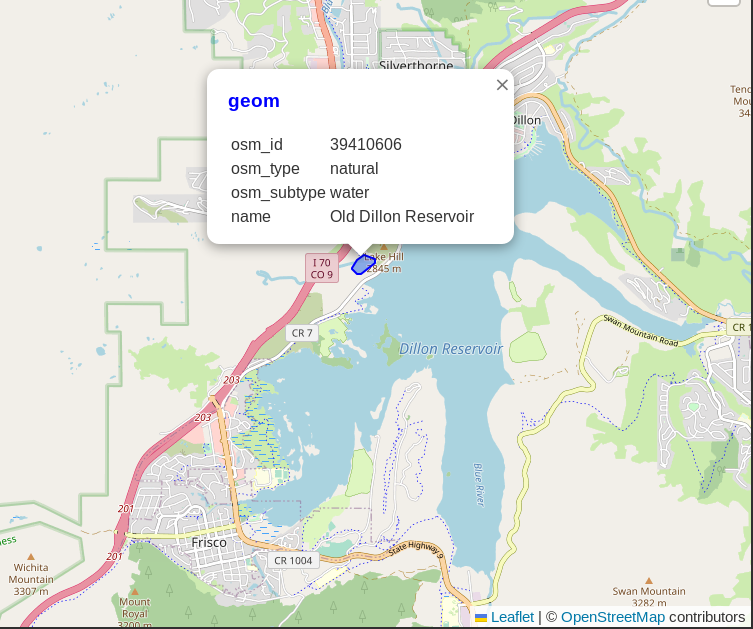
Querying the data loaded by PgOSM Flex 0.6.0 shows the main reservoir is now included
in the results. The calculated area_m column shows the noticeable difference
in size!
SELECT osm_id, osm_type, osm_subtype, name,
ST_Area(ST_Transform(geom, 2773)) AS area_m,
geom
FROM osm.water_polygon
WHERE name ILIKE '%Dillon Reservoir%'
;
┌──────────┬──────────┬─────────────┬──────────────────────┬─────────────┐
│ osm_id │ osm_type │ osm_subtype │ name │ area_m │
╞══════════╪══════════╪═════════════╪══════════════════════╪═════════════╡
│ -1954708 │ natural │ water │ Dillon Reservoir │ 13060398.62 │
│ 39410606 │ natural │ water │ Old Dillon Reservoir │ 58278.22 │
└──────────┴──────────┴─────────────┴──────────────────────┴─────────────┘
Follow-up improvements and breaking changes
The above improvements went into PgOSM Flex 0.5.1. Of course, shortly after
version 0.5.1 was out there I found bugs and other long term issues that needed addressing.
The bugs were due to my quick implementation and were easy enough to address.
The other long term issues revolved around my original decision to
use a materialized view
(osm.vplace_polygon)
in order to remove child geometries included by a parent relation.
Reconsidering this approach resulted in a ⚠️ breaking change ⚠️, hence the
bump to 0.6.0
instead of 0.5.2.
The materialized views
osm.vplace_polygonandosm.places_in_relationsare not created in PgOSM Flex 0.6.0. The de-duplication is now handled by deleting the extra rows from the source table during import.
The trouble with the materialized view approach became apparent when
I started using the same approach for the osm.road_line and osm.water_line
tables. Creating a materialized view
writes the data to disk, which results in two copies of most of that data.
Further, the materialized views need additional indexes, which uses even more disk space.
The following query shows why I didn't really mind the overhead before on the
place_polygon table, and why it started to matter with the water_line
and road_line tables.
SELECT t_name, size_pretty, rows
FROM dd.tables
WHERE s_name = 'osm'
AND t_name IN ('road_line', 'water_line', 'place_polygon')
ORDER BY rows
;
┌───────────────┬─────────────┬────────┐
│ t_name │ size_pretty │ rows │
╞═══════════════╪═════════════╪════════╡
│ place_polygon │ 9448 kB │ 3987 │
│ water_line │ 187 MB │ 443561 │
│ road_line │ 260 MB │ 901777 │
└───────────────┴─────────────┴────────┘
For Colorado, the place data is only 10MB while the road line data is 260 MB. As the size of the region grows (e.g. North America, Europe, Planet) these sizes become considerably larger. Continuing with this approach would significantly increase disk consumption and add non-negligible time to the process of loading and refreshing the OpenStreetMap data. Nobody wants that!
Ease of use
Making PgOSM Flex easy to use has been a big focus. Easy-to-use is a great feature, and I think PgOSM Flex is successful on that front. This is the one project I maintain where I think using Docker is the best approach for both ease of use and reliability. A combination of improvements made the Docker based approach so functional.
Key improvements
The key improvement is that osm2pgsql RAM usage is predictable. Before osm2pgsql 1.5.0, processing required an excessive amount of RAM and it was impossible to really predict how much. With a formula available for RAM consumption, the osm2pgsql-tuner project become a reality to determine the best parameters to use with osm2pgsql.
The PgOSM Flex Docker image uses the logic from osm2pgsql-tuner combined with
a --ram input and the file size of the downloaded .osm.pbf file to determine
the command to run. This makes the Docker image easy to use for all varieties
of region sizes and hardware combinations.
The
osm2pgsql-tunerproject has a free website and API. You can also use it directly from Python usingpip install osm2pgsql-tuner.
Easy to customize
It is easy to
customize how you use
PgOSM Flex via Docker. You can specify an --input-file instead of using
a file downloaded from Geofabrik.
You can define custom layersets
with --layerset and --layerset-path to either modify built-in styles,
or completely replace them with your own styles and post-processing SQL.
If you don't want to use the Docker image you do not have to. The manual import steps cover those details.
See the list of markdown documentation available for more helpful information on using and customizing PgOSM Flex.
Summary
The data provided by PgOSM Flex 0.6.0 is its best quality yet, and it will continue to get better. Now that my book is published I am hoping to have some time to spend looking at the improvements made to geometry processing in osm2pgsql 1.7.0.
Need help with your PostgreSQL servers or databases? Contact us to start the conversation!
 Mastodon
Mastodon