
PgOSM Flex for Production OpenStreetMap data
The PgOSM Flex Project is looking forward to the 0.8.0! If you aren't familiar with PgOSM Flex, it is a tool that loads high quality OpenStreetMap datasets to PostGIS using osm2pgsql. I have a few examples of using OpenStreetMap data loaded this way.
I am extremely excited about PgOSM Flex 0.8.0 because the project as a whole is really starting to feel "production ready." While I have been using PgOSM Flex in production for more than 2 years, there have been a few rough edges over that time. However, the improvements over the past year have brought a number of amazing components together.
PgOSM Flex 0.8.0 does include a few ⚠️ breaking changes! ⚠️ Read the release notes for full details.
PgOSM Flex in production
What does "in production" mean for a tool in a data pipeline?
- Reliable
- Easy to try out
- Easy to load/update to prod
- Low friction software updates
This post covers why I think PgOSM Flex meets all of those requirements.
Reliable
After osm2pgsql reworked its usage of memory (RAM) it was finally possible to create the osm2pgsql-tuner Python package. Adding osm2pgsql-tuner into the mix made it possible to programmatically determine which osm2pgsql command to craft for a give size of hardware, data, and additional considerations (i.e. replication). The improvements to osm2pgsql opened up the ability to package all the "messy bits" into a tidy Docker image.
The net sum is an easy way to run osm2pgsql with a low risk of crashing your server, and a good chance of choosing the options for best performance for the given data size and hardware. Other than Docker, you don't have to install a ton of prerequisites. There's no cloning of repositories, figuring out which set of options to configure appropriately, and hoping you don't crash the server. Everything seems to... just work!
You can still crash the process if you provide a
--ramvalue higher than the amount of RAM available. Typically this value should be set lower than the max available RAM since 100% allocation is never expected.
Easy to try out
PgOSM Flex is easy to try out.
There is a simple Quick Start guide
in the PgOSM Flex documentation. The commands create a directory for the
OpenStreetMap data, set a couple environment variables, then pull, run
and execute a Docker container. The example show shows loading the
district-of-columbia subregion within north-america/us. It only takes a
few minutes to follow the steps in the Quick Start section. When the docker exec
completes, a Postgres/PostGIS instance is running on port 5433
with OpenStreetMap data in the osm schema.
PgOSM Flex downloads the required
data from Geofabrik.
It's easy to change the region loaded by adjusting the --region and --subregion
values.
To change the process to load Ukraine, change --region to europe and
change subregion to ukraine.
docker exec -it \
pgosm python3 docker/pgosm_flex.py \
--ram=8 \
--region=europe \
--subregion=ukraine
Beyond changing the region, there are a handful of common customizations to consider.
Easy to use in production
The built in Postgres/PostGIS instance is handy for testing and quick exploration, it is not intended for production use. The standard way to use PgOSM Flex for production is to connect to an existing external Postgres instance. Using PgOSM Flex this way puts the Docker container to work for the data processing while loading the data to your database.
To use PgOSM Flex with your external Postgres instance you will want to to setup the database with a user configured with appropriate permissions. These initial steps are documented on the Postgres Permissions page.
Sure, it's possible (and arguably easier) to use a superuser login role. Don't do that!
With a Postgres role setup with appropriate permissions configure the Docker container for the external connection. If it's a one time data load that is all you need. If you want to update your data occasionally check out the additional details in the replication section.
External Connection and Replication
This section shows the commands I run to update the OpenStreetMap data in my production databases using PgOSM Flex.
Running source ~/.pgosm-db-myproject sets the necessary environment variables,
the contents of the file are explained in the documentation.
To switch between projects/databases, I adjust the first line pointing the the
environment variables. The other adjustments to make to this example are for the
region and subregion to load, and often changing the --layerset.
One nice part about this process is the same commands can be used for both the first import and every subsequent update via replication.
source ~/.pgosm-db-myproject
docker run --name pgosm -d --rm \
-v ~/pgosm-data:/app/output \
-v /etc/localtime:/etc/localtime:ro \
-e POSTGRES_USER=$POSTGRES_USER \
-e POSTGRES_PASSWORD=$POSTGRES_PASSWORD \
-e POSTGRES_HOST=$POSTGRES_HOST \
-e POSTGRES_DB=$POSTGRES_DB \
-e POSTGRES_PORT=$POSTGRES_PORT \
-p 5433:5432 -d rustprooflabs/pgosm-flex:0.7.2
docker exec -it \
pgosm python3 docker/pgosm_flex.py \
--ram=8 \
--region=north-america/us \
--subregion=colorado \
--replication
PgOSM Flex imports are tracked in the target database using the osm.pgosm_flex table.
The 0.8.0 release is bringing some improvements to the osm.pgosm_flex table.
The following query shows the new layerset column, and the improved import_status
column (new in 0.7.1).
SELECT osm_date, region, pgosm_flex_version, layerset, import_status
FROM osm.pgosm_flex
ORDER BY imported DESC
;
Results
┌────────────┬───────────────────────────┬─────────────────────┬──────────┬───────────────┐
│ osm_date │ region │ pgosm_flex_version │ layerset │ import_status │
╞════════════╪═══════════════════════════╪═════════════════════╪══════════╪═══════════════╡
│ 2023-04-18 │ north-america/us-colorado │ 0.8.0-dev.1-dcd6454 │ default │ Completed │
│ 2023-03-26 │ north-america/us-colorado │ 0.7.2-0b91c81 │ ¤ │ ¤ │
└────────────┴───────────────────────────┴─────────────────────┴──────────┴───────────────┘
Low friction upgrades
With PgOSM Flex, everything is bundled into the
Docker image.
The process to update to the latest of PgOSM Flex is a simple docker pull command.
If you want a specific tagged version, swap out latest for the version number.
docker pull rustprooflabs/pgosm-flex:latest
If you are using --replication you will need to pay attention to your version numbers
(aka don't use :latest!) and watch the release notes
for manual steps required in the "Upgrade notes for --replication".
Some changes to the structure created by PgOSM Flex require manual steps
to keep replication running smoothly as PgOSM Flex is updated.
Beware max_connections
My only real concern with running PgOSM Flex against production instances is related
to connection volume with --replication.
Replication should reduce load times significantly of subsequent updates.
However, the
current osm2pgsql connection model
opens and holds 3 + (1 + number of threads) * number of tables for the duration
of processing. This works great with the legacy 3-table OpenStreetMap data structure
(point, line and polygon tables). By splitting data out in meaningful subgroups,
this results in quite a large overhead in terms of available connections.
SELECT s_name, COUNT(*) AS table_count,
3 + (1 + 1) * COUNT(*) AS required_connections_lower,
3 + (1 + 4) * COUNT(*) AS required_connections
FROM dd.tables
WHERE s_name = 'osm'
GROUP BY s_name
;
┌────────┬─────────────┬────────────────────────────┬──────────────────────┐
│ s_name │ table_count │ required_connections_lower │ required_connections │
╞════════╪═════════════╪════════════════════════════╪══════════════════════╡
│ osm │ 41 │ 85 │ 208 │
└────────┴─────────────┴────────────────────────────┴──────────────────────┘
The above query uses the dd.tables view from our
PgDD extension
to calculate how many connections are needed with the default layerset.
The default layerset uses 41 tables, so needs 85 - 208 connections depending
on 1 to 4 threads.
Considering the Postgres default for max_connections = 100 this will
catch folks off guard.
Some positive news is Postgres versions 14 and newer continue to improve
performance with higher connection
volumes, so hopefully this isn't too big of an issue.
Check your connection limit with
SHOW max_connections;and consider increasing this value to give a bit more headroom! If resource constrained, you may want to consider skipping replication and using--pg-dumpto transfer data into production.
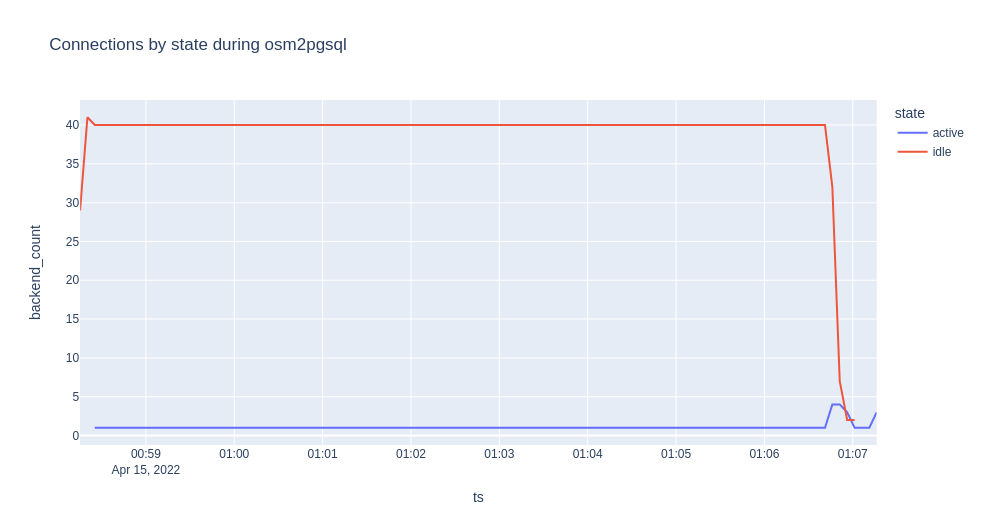
Unfortunately, the bulk of the connections are not even actively used during the majority of the processing time. The vast majority appear to be used a brief amount at the very beginning, and then gain at the very end of processing. The remainder of the time is simply holding idle connections. The following chart from this comment shows one example of what I found related to connection handling.
Summary
PgOSM Flex is an easy to use tool to load OpenStreetMap data into PostGIS. The data loaded is high quality, ready to use, and if it doesn't suit your exact needs out of the box, customization is in mind at every level.
I'm obviously biased, though I think you will find it a helpful tool as well!
Need help with your PostgreSQL servers or databases? Contact us to start the conversation!
 Mastodon
Mastodon