
OpenStreetMap to PostGIS is getting lighter
If you have ever wanted OpenStreetMap data in Postgres/PostGIS, you are probably familiar with the osm2pgsql tool. Lately I have been writing about the osm2pgsql developments with the new Flex output and how it is enabling improved data quality. This post changes focus away from the flex output and examines the performance of the osm2pgsql load itself.
One challenge with osm2pgsql over the years has been generic
recommendations have been difficult to make. The safest recommendation
for nearly any combination of hardware and source data size was
to use osm2pgsql --slim --drop to put most of the intermediate data
into Postgres instead of relying directly on RAM, which it needed a lot of.
This choice has offsetting costs of putting all that data into Postgres (only to be deleted) in terms of disk usage and I/O performance.
A few days ago, a pull request from Jochen Topf to create a new RAM middle caught my eye. The text that piqued my interest (emphasis mine):
When not using two-stage processing the memory requirements are much much smaller than with the old ram middle. Rule of thumb is, you'll need about 1GB plus 2.5 times the size of the PBF file as memory. This makes it possible to import even continent-sized data on reasonably-sized machines.
Wait... what?! Is this for real??
Predictable RAM requirements
The idea of having much smaller memory requirements is great. What is even better than reducing memory requirements? Making the requirements possible to calculate at all!
How much RAM does North America osm.pbf
(10.4 GB) require to load without --slim? Through osm2pgsql v1.4.2: I don't know!
I do know North America requires more RAM than a 64GB instance can provide
but I got tired of trying to find the right size for every import.
I also didn't think that spooling up a server with 128GB or more RAM
really made sense to process a 10 GB file. So, for years I have blindly
used --slim --drop for everything. Because it worked.
But, now we have a formula!
1GB plus 2.5 times the size of the PBF file
A quick bit of Python felt like the right thing to do.
osm_pbf_gb = 10.4
osm2pgsql_cache_required_gb = 1 + (2.5 * osm_pbf_gb)
print(f'You need {osm2pgsql_cache_required_gb} GB')
This reported You need 27.0 GB. Fantastic, that should work nicely on a
server with 64 GB RAM.
Then, on to proclaim my excitement with this discovery.
osm2pgsql (w/out --slim) should now run with far less memory!
— RustProof Labs 🐘 (@RustProofLabs) April 30, 2021
"you'll need about 1GB plus 2.5 times the size of the PBF file as memory"
North America PBF = 10.4GB
1 GB + (10.4 GB * 2.5) = 27 GB
Really?! #gischat 🤓🎉https://t.co/n8blYH4cfN
Test the new RAM middle
At this point I had to try it out and see if it really does work. What I understood from that PR is this command should work. I also expect the tagged osm2pgsql v1.4.2 release (without this patch) will fail when using this same command on the same hardware.
time osm2pgsql \
--output=flex --style=./run-all.lua \
-d $PGOSM_CONN \
~/pgosm-data/north-america-latest.osm.pbf
Update 5/4/2021: This post originally included
--cache=27648in theosm2pgsqlcommand, that has been removed. I learned that the--cacheparameter is ignored and osm2pgsql will attempt to claim as much cache as it needs. Thanks again, Jochen!!
To test, I created a Memory Optimized droplet with 8 vCPU and 64 GB RAM. This gives room for the 27 GB cache for osm2pgsql while leaving plenty of room for Postgres to do its part. PostgreSQL 13 is installed on the same server and configured per Tuning the PostgreSQL Server in the osm2pgsql docs. The osm2pgsql Flex output was used with PgOSM-Flex styles following the steps outlined in MANUAL-STEPS-RUN.md.
New middle
With the latest master branch of osm2pgsql installed
osm2pgsql --version returned:
osm2pgsql version 1.4.2 (1.4.2-49-gac7e1c3e)
This should be an early peek at what will be in osm2pgsql
v1.4.3 v1.5.0
(release notes).
With this version installed I ran the osm2pgsql ... command from above.
And...
<pause for dramatic effect />
It worked!
osm2pgsql took 20531s (5h 42m 11s) overall.
It took 5 hours 42 minutes for osm2pgsql to process the run-all layer set.
I have not documented timings for the run-all layer set but this
seems in line with the timings I documented for the
no-tags layer set. The osm.tags table is the only difference, but it's a noticeable difference.
Old middle
Now I had to double check that the same command would not work using the
old middle processing.
I checked out the 1.4.2 tag of osm2pgsql and anxiously watched and
waited for it to fail. It had to fail, right? Or would it work?
After all, it had been at least 2 or 3 years since I had even bothered to
try this without --slim --drop.
After 207 minutes (nearly 3.5 hours), the command failed with a simple
Killed message.
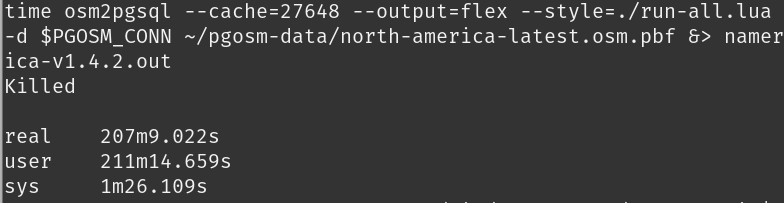
This is why I use the
timecommand with osm2pgsql. osm2pgsql will report timings, but only if it doesn't crash!
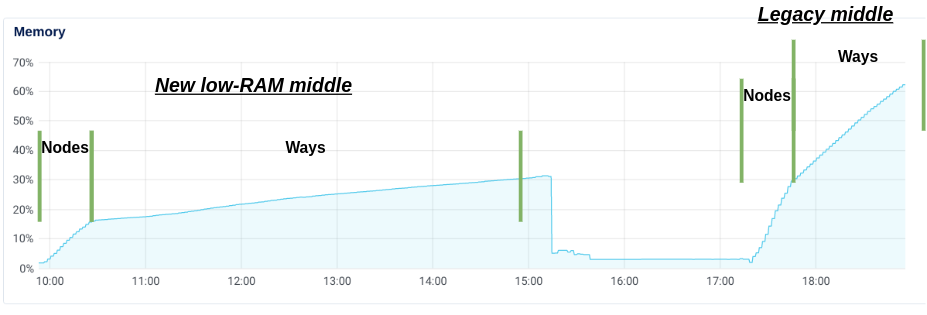
The following screenshot from Digital Ocean's monitoring shows the full process of the successful run (with the patch) and the beginning portion of the failed run (v1.4.2). The new low-RAM middle reported a max of a little over 30% of the server's RAM being used at the end. Using the legacy middle, 30% of the RAM was consumed just processing the nodes! The consumption through the ways continues to grow significantly faster than with the new method, eventually eating up all 64GB (plus the 4 GB swap file) to fail.
Summary
This is a great improvement to osm2pgsql! All I have done so far is verify
the change works as anticipated, and it does. More testing is sure
to follow. I plan to explore how the performance differs between the in-RAM
import and a --slim --drop import. It will be interesting to see what
the effect is on overall time as well as the impact on the Postgres
instance itself.
Need help with your PostgreSQL servers or databases? Contact us to start the conversation!
 Mastodon
Mastodon