
Hands on with osm2pgsql's new Flex output
The osm2pgsql project has seen quite a bit of development over the past couple of years. This is a core piece of software used by a large number of people to load OpenStreetMap data into PostGIS / PostgreSQL databases, so it has been great to see the activity and improvements. Recently, I was contacted by Jochen Topf to see if I would give one of those (big!) improvements, osm2pgsql's new Flex output, a try. While the flex output is still marked as "experimental" it is already quite robust. In fact, I have already started thinking of the typical pgsql output I have used for nearly a decade as "the old output!"
So what does this new Flex output do for us? It gives us control over the imported data's format, structure and quality. This process uses Lua styles (scripts) to achieve powerful results. The legacy pgsql output from osm2pgsql gave you three (3) main tables with everything organized into points, lines and polygons, solely by geometry type. From a database design perspective this would be like keeping product prices, employee salaries and expense reports all in one table using the justification "they all deal with money." With the flex output we are no longer constrained by this legacy design. With that in mind, the rest of this post explores osm2pgsql's Flex output.
This post is part of the series PostgreSQL: From Idea to Database. There are a number of posts covering osm2pgsql, the data structure in PostGIS, and how I have historically restructured and cleaned this data.
Version tested
This post used a local install of osm2pgsql 1.4.0 built from source, PostgreSQL 13.1, and PostGIS 3.0.3.
osm2pgsql --version
2020-12-07 17:38:41 osm2pgsql version 1.4.0 (1.4.0)
Compiled using the following library versions:
Libosmium 2.15.6
Proj [API 4] Rel. 6.3.1, February 10th, 2020
Lua 5.3.3
Starting with Flex
To get started with the new Flex output read the flex output documentation on
osm2pgsql's website
and explore the Lua scripts in the project's repo
under the flex-config directory.
The readme in that directory gives a recommended order for reading through the
Lua pages.
Have you noticed the osm2pgsql.org website?! That's new too! Documentation that may have previously been on the GitHub repo or random Wiki pages are now in one organized place.
JSONB
A quick bonus is the Flex backend can store key/value data in
Postgres' native JSONB data type!
The osm2pgsql project predates JSON in Postgres and has long used the
HSTORE extension for storing key/value data in the tags column.
As I switch to the flex output I plan to completely retire the use of HSTORE
in our databases in favor of the JSONB data type.
Modern Postgres has seen a number of JSON related improvements,
doesn't require installing an extra extension, and
developers in general are more familiar with JSON.
Using JSON support with osm2pgsql requires an additional package (Ubuntu/Debian).
sudo apt install lua-dkjson
Now Lua scripts can include dkjson.
-- Use JSON encoder
local json = require('dkjson')
Later in the code when the tags data is added to the row, this line:
tags = object.tags,
Becomes this line:
tags = json.encode(object.tags),
Style for Roads
The styles referenced in this post are available under the flex-config directory
within the PgOSM repo. The road.lua script was the first place I started.
The road table has a few additional columns defined, including name,
ref (e.g. I-70 for "Interstate 70"), maxspeed (in km/hr).
This step also allows me to put the table in a schema,
so into the osm schema it goes!
tables.highways = osm2pgsql.define_way_table('road_line',
{
{ column = 'osm_type', type = 'text', not_null = true },
{ column = 'name', type = 'text' },
{ column = 'ref', type = 'text' },
{ column = 'maxspeed', type = 'int' },
{ column = 'oneway', type = 'direction' },
{ column = 'tags', type = 'jsonb' },
{ column = 'geom', type = 'linestring' },
},
{ schema = 'osm' }
)
The equivalent SQL query to create the table defined above would look like
the following query.
Note the way_id column below is not defined above, nor is the GIST index on the geom column. That's because the
functions to define tables auto-magically add those details for us.
CREATE TABLE osm.road_line
(
way_id BIGINT NOT NULL,
osm_type TEXT NOT NULL,
name TEXT,
ref TEXT,
maxspeed INT,
oneway SMALLINT,
tags JSONB,
geom GEOMETRY (LINESTRING, 3857)
);
CREATE INDEX road_line_geom_idx
ON osm.road_line USING GIST (geom);
The osm2pgsql.process_way() function orchestrates the rest of the magic
to process highway lines in this script.
The if not logic used at the beginning discards data that does not have
a highway tag. The functions clean_tags() and parse_speed() are pulled directly
from examples in the osm2pgsql repo. (I told you to look at those Lua examples!)
The parse_speed() function is especially useful, standardizing the maxspeed
column into numeric data in km/hr.
The use of object:grab_tag('<tagname>') works like list.pop() in Python,
both returning a value and removing the key/value from the remaining object.tags.
There are ways to pull data out of the tags without using grab_tag() but this
will unnecessarily duplicate data stored in columns if the tags data is also being saved to Postgres.
function osm2pgsql.process_way(object)
-- We are only interested in highways
if not object.tags.highway then
return
end
clean_tags(object.tags)
-- Using grab_tag() removes from remaining key/value saved to Pg
local name = object:grab_tag('name')
local osm_type = object:grab_tag('highway')
local ref = object:grab_tag('ref')
-- in km/hr
maxspeed = parse_speed(object.tags.maxspeed)
oneway = object:grab_tag('oneway') or 0
tables.highways:add_row({
tags = json.encode(object.tags),
name = name,
osm_type = osm_type,
ref = ref,
maxspeed = maxspeed,
oneway = oneway,
geom = { create = 'line' }
})
end
Run osm2pgsql with custom Flex style
With the road.lua style in place it's time to test it out.
First, we need some data. I like to use
the Washington D.C. sub-region for testing because it's small (PBF is 17 MB) and loads and processes quickly (8 seconds).
wget https://download.geofabrik.de/north-america/us/district-of-columbia-latest.osm.pbf
The first and third lines of the following osm2pgsql command are much like
what I typically use. The
second line defining --output=flex and the --style are the new pieces for this test.
osm2pgsql --slim --drop \
--output=flex --style=./road.lua \
-d pgosm /data/osm/osm2pgsql-flex/district-of-columbia-latest.osm.pbf
The output from running osm2pgsql has been improved quite a bit, even since version 1.2.0.
2020-12-07 17:44:42 osm2pgsql version 1.4.0 (1.4.0)
2020-12-07 17:44:42 Database version: 13.1 (Ubuntu 13.1-1.pgdg20.04+1)
2020-12-07 17:44:42 Node-cache: cache=800MB, maxblocks=12800*65536, allocation method=11
Processing: Node(31010k 1348.3k/s) Way(2607k 130.35k/s) Relation(15399 15399.0/s) parse time: 43s
2020-12-07 17:45:25 Node stats: total(31010654), max(8181118446) in 23s
2020-12-07 17:45:25 Way stats: total(2607090), max(879451695) in 20s
2020-12-07 17:45:25 Relation stats: total(15399), max(11961674) in 0s
2020-12-07 17:45:25 No marked ways (Skipping stage 2).
2020-12-07 17:45:25 Dropping table 'planet_osm_nodes'
2020-12-07 17:45:26 Done postprocessing on table 'planet_osm_nodes' in 1s
2020-12-07 17:45:26 Dropping table 'planet_osm_ways'
2020-12-07 17:45:26 Done postprocessing on table 'planet_osm_ways' in 0s
2020-12-07 17:45:26 Dropping table 'planet_osm_rels'
2020-12-07 17:45:26 Done postprocessing on table 'planet_osm_rels' in 0s
2020-12-07 17:45:26 Clustering table 'road_line' by geometry...
2020-12-07 17:45:30 Creating geometry index on table 'road_line'...
2020-12-07 17:45:34 Analyzing table 'road_line'...
2020-12-07 17:45:34 All postprocessing on table 'road_line' done in 8s.
2020-12-07 17:45:34 Osm2pgsql took 52s overall.
2020-12-07 17:45:34 node cache: stored: 31010654(100.00%), storage efficiency: 53.77% (dense blocks: 1448, sparse nodes: 22906137), hit rate: 100.00%
Timestamps are everywhere, very helpful. Otherwise the output doesn't look all that exciting... except the last few lines mentioning road_line! That shows that
the custom road.lua script indeed did process the highway data.
Take a peek at a single row from the osm.road_line table.
SELECT way_id, osm_type, name, ref, maxspeed, oneway, tags
FROM osm.road_line
LIMIT 1
;
Results show about what I expect. The value from highway is in the osm_type
column. The name and maxspeed were populated and there are a bunch of additional keys in the tags column that were removed (e.g. tiger:*) by default
in the standard output.
Right now I'm thinking some of these additional keys might be helpful so they
are left in for now. If I don't end up using them for anything, it will be easy
enough to remove them in the future.
┌─────────┬─────────────┬──────────────┬─────┬──────────┬────────┬─────────────────────────────────┐
│ way_id │ osm_type │ name │ ref │ maxspeed │ oneway │ tags │
╞═════════╪═════════════╪══════════════╪═════╪══════════╪════════╪═════════════════════════════════╡
│ 5970388 │ residential │ Holly Avenue │ ¤ │ 40 │ 0 │ {"lanes": "2", "surface": "asph…│
│ │ │ │ │ │ │…alt", "maxspeed": "25 mph", "ti…│
│ │ │ │ │ │ │…ger:cfcc": "A41", "tiger:county…│
│ │ │ │ │ │ │…": "Montgomery, MD", "tiger:zip…│
│ │ │ │ │ │ │…_left": "20912", "tiger:name_ba…│
│ │ │ │ │ │ │…se": "Holly", "tiger:name_type"…│
│ │ │ │ │ │ │…: "Ave", "tiger:zip_right": "20…│
│ │ │ │ │ │ │…912"} │
└─────────┴─────────────┴──────────────┴─────┴──────────┴────────┴─────────────────────────────────┘
Run post-import SQL
After loading the data it's good to document with comments,
enforce constraints, and consider non-spatial indexes for common query patterns.
I put the following code in an accompanying road.sql script.
This can easily be ran with psql -d pgosm -f ./road.sql right after the osm2pgsql command.
COMMENT ON TABLE osm.road_line IS 'Generated by osm2pgsql Flex output using pgosm/flex-config/road.lua';
COMMENT ON COLUMN osm.road_line.osm_type IS 'Value from "highway" key from OpenStreetMap data. e.g. motorway, residential, service, footway, etc.';
ALTER TABLE osm.road_line
ADD CONSTRAINT pk_osm_road_line_way_id
PRIMARY KEY (way_id)
;
CREATE INDEX ix_osm_road_line_highway ON osm.road_line (osm_type);
Creating the
PRIMARY KEYonway_idis now possible because the style did not define asplit_atvalue. Thesplit_atoptions allows splitting longer lines into shorter segments.
Combining Styles
The approach described in this section did not work but paved the way for a solution that did work. See my next post for more on the method that does work.
Other than the road.lua style, I started drafting two additional styles.
One for natural points
(tree, peak, etc) and another for building polygons. These are available
in the PgOSM repo
in the natural.lua and building.lua scripts. Each .lua script has an
associated .sql script to run post-import.
The original PgOSM project is deprecated. See the PgOSM-Flex project for the latest version of the osm2pgsql flex styles.
I am attempting to develop each logical grouping for data as a standalone Lua script. This is an attempt to turn logical groupings of data into distinct components that can be included, or not, easily on a per-project basis. Maybe one project needs roads, traffic signals, parking lots and buildings while another project needs roads, waterways, and mountain peaks. Why should both projects have to define roads instead of having one common road definition for each project?
After not finding this feature documented within osm2pgsql, I asked Jochen to make sure I wasn't missing something obvious. His suggestion was to include the Lua scripts from a different Lua script. I tried running two Lua scripts from a third script like this.
require "road"
require "natural"
This seemed to work exactly as I needed. I ended up with data loaded for the roads and the natural points.
Unfortunately, continued testing by adding in a 3rd Lua script (building.lua)
exposed a shortcoming with this simple solution. Even though it
seemed like the following attempt ran OK (no errors from osm2pgsq1), when I checked in Postgres the osm.road_line table was empty.
require "natural"
require "road"
require "building"
After a quick review of the Lua code, I realize both the natural and building scripts
have a function osm2pgsql.process_way(object). The simple method using
require falls apart with the later definition of same-named functions
being retained and executed, and the earlier osm2pgsql.process_way() definition
is discarded.
It should be noted that before this round of testing I had never used Lua. It seems likely that in my quick searching of this problem combined with my lack of experience in the language, I missed finding the more elegant solution. I will absolutely be following up on how to make this work, but for now it is time to move on!
Multiple PBF inputs
On to a feature that is not directly tied to the new flex output. One of the release notes from the release notes for osm2pgsql 1.4.0 caught my eye with mention of handling multiple input files.
osm2pgsql 1.4.0 is here!
— RustProof Labs (@RustProofLabs) December 7, 2020
"Osm2pgsql now reads multiple input files at the same time merging the contents. This means that you can now import several extracts in one go." 😍https://t.co/nokY4Umi2x
Previously if I wanted the roads and buildings (a common pairing I use)
for a collection of five (5) U.S. states I would import the entire U.S.
or even North America. I would then run the PgOSM transformations I need and
dump out the subset(s) of data I was going for.
As I've
shown before,
loading North America with --flat-nodes requires somewhere in the ballpark of 200GB for the temporary data in PostGIS, the flat nodes file, the source file, and the data itself. On hardware with 16 CPU and 128 GB RAM it
took an hour or so to load the data in. Then it would require processing, filtering,
etc. back down. All of this kept me from doing a lot of that type of work on my local device, often spinning up temporary instances to do the work.
Now, if I want the roads and buildings for 5 states I can run a command like the following once for each Lua style that needs loading.
osm2pgsql --slim --drop --cache 30000 \
--output=flex --style=./road.lua \
-d pgosm \
/data/osm/osm2pgsql-flex/colorado-latest.osm.pbf \
/data/osm/osm2pgsql-flex/wyoming-latest.osm.pbf \
/data/osm/osm2pgsql-flex/nebraska-latest.osm.pbf \
/data/osm/osm2pgsql-flex/kansas-latest.osm.pbf \
/data/osm/osm2pgsql-flex/utah-latest.osm.pbf
The above command runs on my laptop in less than 2 minutes! The total size of the PBF files was 437 MB.
Osm2pgsql took 117s (1m 57s) overall.
I could create a combined Lua script that does it all in one, but right now I am still holding out hopes for being able to keep my small definitions and combine as necessary per project.
Running the building.lua (1 min, 42s) and natural.lua (1min 11s) scripts took
the total time to load three layers from 5 PBF files to 4 minutes and 50 seconds.
This approach currently requires combining and loading the PBF files three (3) times instead of only once, that time makes up 80% of the total time.
My prior approach of loading North America and taking out what I needed
took significantly more time.
So what was loaded in just under 5 minutes? 1.5 million building polygons, 2.1 million road segments and 185k natural points. The total size on disk of the data and indexes is about 1.3 GB.
SELECT s_name, t_name, rows, size_pretty, size_plus_indexes
FROM dd.tables
WHERE s_name = 'osm'
;
s_name|t_name |rows |size_pretty|size_plus_indexes|
------|----------------|---------|-----------|-----------------|
osm |building_polygon|1529147.0|376 MB |448 MB |
osm |road_line |2103217.0|787 MB |900 MB |
osm |natural_point | 385250.0|30 MB |48 MB |
The above query uses the PgDD Data Dictionary extension
Now, a map
All of this talk about data and code... how about a map? The following image shows the 2.1 million roads with a faint OpenStreetMap basemap overlap.
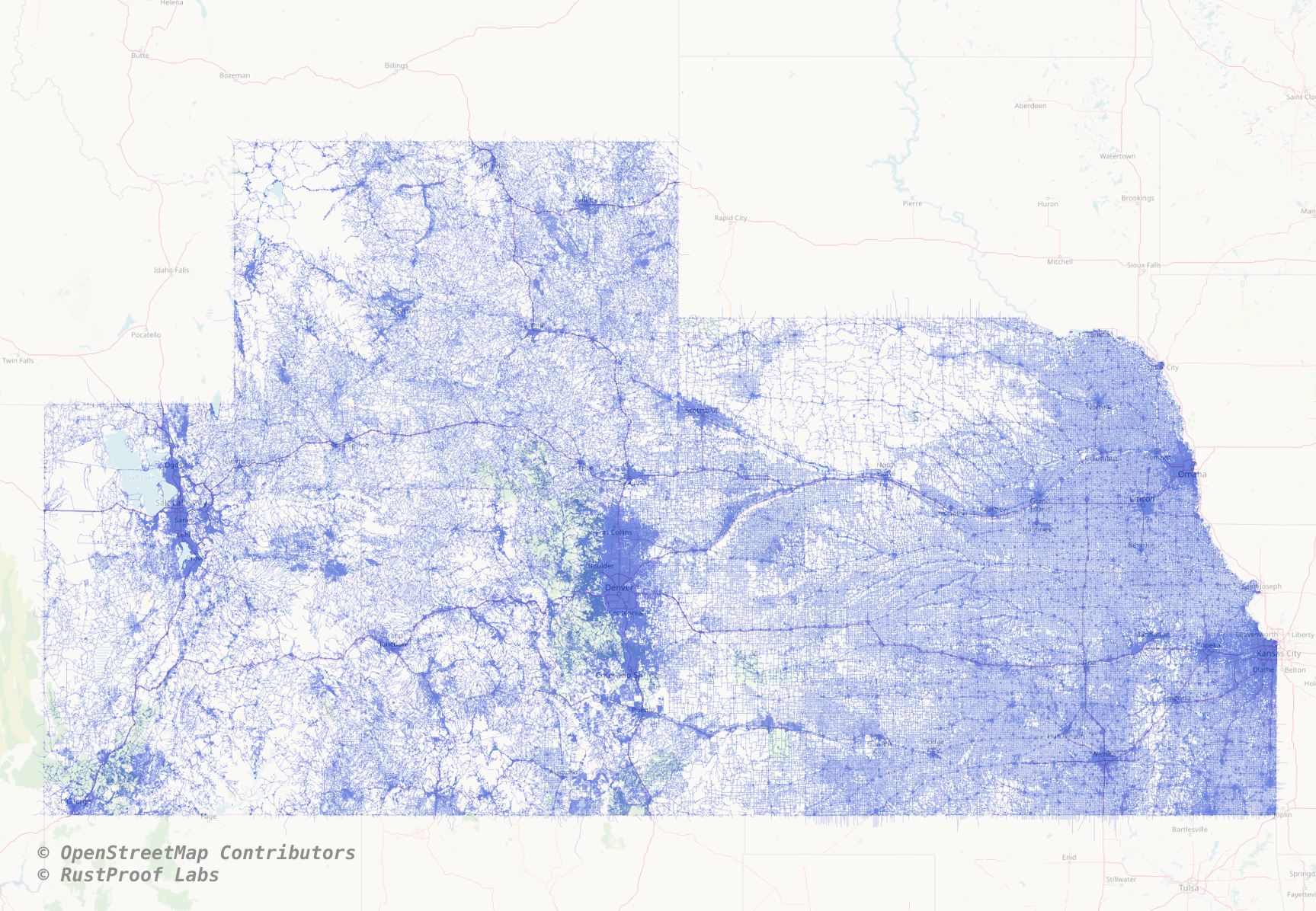
Summary
I am really excited for the new flex output from osm2pgsql! What I have done so far with it is just starting to scratch the surface. It will take me a while to full phase out the legacy format, but for all new purposes I plan to start using the Flex output.
The ability to control the structure and improve data quality for your project's specifications is key. The Lua styles are pretty easy to write and modify once you get the hang of the structure.
Need help with your PostgreSQL servers or databases? Contact us to start the conversation!
 Mastodon
Mastodon