
Postgres 13 Performance with OpenStreetMap data
With Postgres 13 released recently, a new season of testing has begun! I recently wrote about the impact of BTree index deduplication, finding that improvement is a serious win. This post continues looking at Postgres 13 by examining performance through a few steps of an OpenStreetMap data (PostGIS) workflow.
Reasons to upgrade
Performance appears to be a strong advantage to Postgres 13 over Postgres 12. Marc Linster wrote there's "not one headline-grabbing feature, but rather a wide variety of improvements along with updates to previously released features." I am finding that to be an appropriate description. At this point I intend to upgrade our servers for the improved performance, plus a few other cool benefits.
I am already using Postgres 13 for some dev servers. One of the features I helped review is very helpful when working through development. Before Postgres 13, dropping a database when a connection exists used to cause an error that was easiest to fix by restarting the Postgres service.
([local] 🐘) ryanlambert@postgres=# DROP DATABASE demo;
ERROR: database "demo" is being accessed by other users
DETAIL: There is 1 other session using the database.
Now with Postgres 13 we can use the FORCE option, no more pesky errors.
([local] 🐘) ryanlambert@postgres=# DROP DATABASE demo WITH (FORCE);
DROP DATABASE
Last year when I first reviewed Postgres 12, I concluded performance was in-line with Postgres 11. My decision to upgrade to Postgres 12 from 11 at that time was largely due to new features. With Postgres 13 providing improvements to performance among many other improvements, if you are still on Postgres 11 or older I would strongly consider upgrading!
Versions Tested
This post used the latest minor versions of Postgres available at the time of writing.
- 13.0
- 12.4
- 11.9
PostGIS was version 3.02, and osm2pgsql 1.3.0.
Data and hardware
This post used a single Digital Ocean droplet with 4 CPU and 8 GB RAM ("Rig B" from Scaling osm2pgsql: Process and costs). The Colorado region is loaded from Geofabrik using this process, and takes up about 1.3 GB in Postgres when processed through PgOSM. Each version of Postgres was installed on a single machine with only the Postgres version being tested running during the tests. Timings provided are the average of at least three runs.
My notes for this post started when Postgres 13 Beta 2 was available. Overlapping test results from Beta 2, Beta 3, and 13.0 confirm the overall trends documented here.
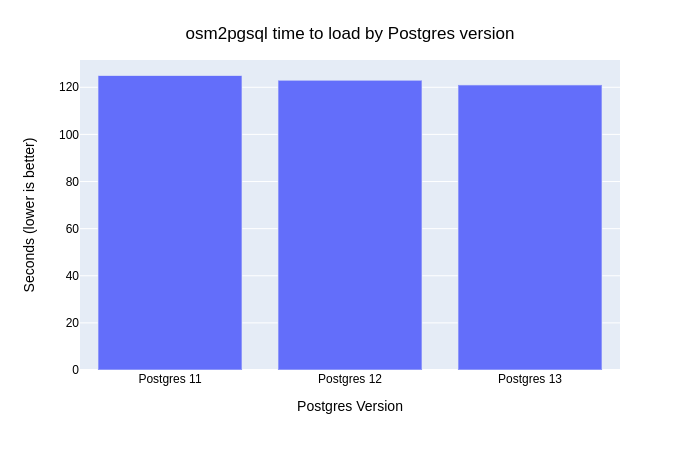
Time running osm2pgsql
The first step of loading OpenStreetMap data is to load it
through osm2pgsql.
The majority of the work done by osm2pgsql is unpacking the compressed
osm.pbf file and pushing it into the database. Since so much of the processing
in this step is happening outside of Postgres, the potential gains here by simply
upgrading Postgres are limited. Postgres 13 was still a small margin (3%) faster
than Postgres 11 (121 seconds vs. 125 seconds) when using osm2pgsql
to load Colorado to PostGIS.
Time running PgOSM
The second step is to prepare the structure of OpenStreetMap data by running it through
PgOSM.
All but a tiny amount of
processing happens within Postgres/PostGIS on this step.
The transformations use a series of SQL statements consisting
of CREATE TABLE <foo> AS SELECT ... WHERE <bar>, followed by the creation of a GIST index on each table.
This step is where Postgres improvements can have
an larger impact. Postgres 13 was 18% faster than Postgres 11 and 12% faster than Postgres 12!
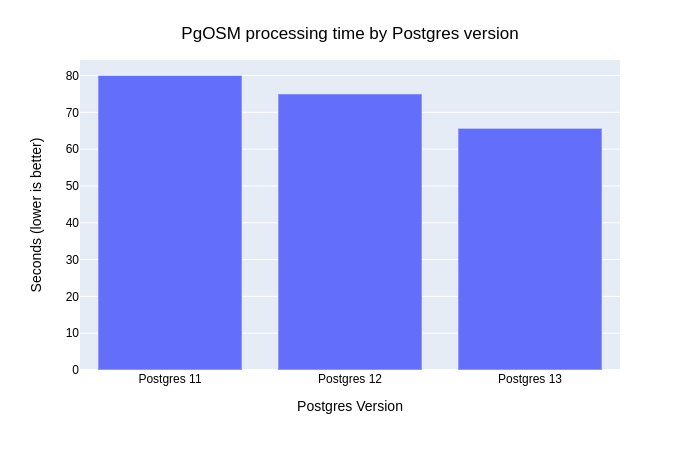
The net effect on the ETL time (osm2pgsql and PgOSM) is 9% faster when using Postgres 13!
Testing with pgbench
Our pgbench-tests repo
has a couple test queries that use Colorado's OpenStreetMap PostGIS data.
For this post I'll reuse tests/openstreetmap/pgosm--co-jeffco-trees-benches.sql.
That test query was used when putting
Postgres 12 on the Raspbery Pi 4
to the test, and was examined in our recorded session
PostGIS Queries and Performance (4/6).
The transactions per second (TPS) on Postgres 11 and 12 are relatively close to each other at 130 and 132 TPS. Postgres 13 came in at 151 TPS, 16% faster!
pgbench -c 10 -j 2 -T 600 --no-vacuum \
-f tests/openstreetmap/pgosm--co-jeffco-trees-benches.sql \
pgosm

While proper benchmarking should run considerably longer than 10 minutes, this level of testing provides sufficient data for the purpose of this post.
BTree Indexes
My last post covering the
BTree index deduplication
in Postgres 13 showed significant savings in the size of btree indexes.
It also showed the change has the most significant impact when created indexes on
columns with duplication.
To look closer at this we look at the columns available in osm.building_polygon
made available from PgOSM.
A query in the pg_catalog.pg_stats table shows a few columns that each have
a handful of distinct values. The building column is often used for filtering and
n_distinct=65 indicates it's a good candidate to take advantage of the btree deduplication.
SELECT s.tablename, s.attname AS column_name, s.n_distinct
FROM pg_catalog.pg_stats s
WHERE s.tablename = 'building_polygon'
AND s.n_distinct > 0
ORDER BY s.n_distinct
LIMIT 5
;
┌──────────────────┬─────────────┬────────────┐
│ tablename │ column_name │ n_distinct │
╞══════════════════╪═════════════╪════════════╡
│ building_polygon │ height │ 1 │
│ building_polygon │ code │ 1 │
│ building_polygon │ levels │ 16 │
│ building_polygon │ building │ 65 │
│ building_polygon │ operator │ 183 │
└──────────────────┴─────────────┴────────────┘
Note:
n_distinctis estimated! Your results will likely vary a small amount from the values shown here! RunningANALYZEwill often produce different estimates even when the data has not changed.
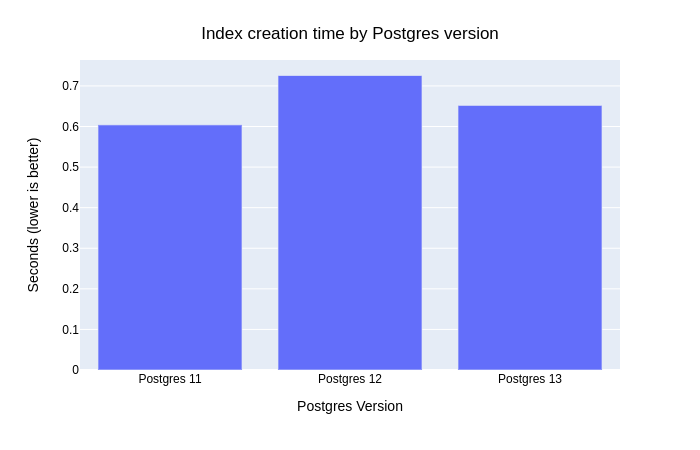
Index Creation Time
Create an index on the building column. Postgres 13 is faster than Postgres 12,
but still slower than Postgres 11.
CREATE INDEX ix_osm_building_class
ON osm.building_polygon (building)
;
BTree Index size
With the index created we can query the index size.
SELECT ai.schemaname AS s_name, ai.relname AS t_name,
ai.indexrelname AS index_name,
pg_size_pretty(pg_relation_size(quote_ident(ai.schemaname)::text || '.' || quote_ident(ai.indexrelname)::text)) AS index_size,
pg_relation_size(quote_ident(ai.schemaname)::text || '.' || quote_ident(ai.indexrelname)::text) AS index_size_bytes
FROM pg_catalog.pg_stat_all_indexes ai
WHERE ai.indexrelname LIKE 'ix_osm_building%'
ORDER BY index_size_bytes DESC
;
Postgres 11 and 12 create a 17 MB index.
┌────────┬──────────────────┬───────────────────────┬────────────┬──────────────────┐
│ s_name │ t_name │ index_name │ index_size │ index_size_bytes │
╞════════╪══════════════════╪═══════════════════════╪════════════╪══════════════════╡
│ osm │ building_polygon │ ix_osm_building_class │ 17 MB │ 18284544 │
└────────┴──────────────────┴───────────────────────┴────────────┴──────────────────┘
Postgres 13 creates a 5.2 MB file, a 69% reduction in size from prior versions.
┌────────┬──────────────────┬───────────────────────┬────────────┬──────────────────┐
│ s_name │ t_name │ index_name │ index_size │ index_size_bytes │
╞════════╪══════════════════╪═══════════════════════╪════════════╪══════════════════╡
│ osm │ building_polygon │ ix_osm_building_class │ 5320 kB │ 5447680 │
└────────┴──────────────────┴───────────────────────┴────────────┴──────────────────┘
BTree Index performance
Using the handy tool, EXPLAIN, allows us to see the reduction in index
size manifest in query plans. One output was captured
from Postgres 11 and
Postgres 13. Both plans use a Bitmap
index scan on the index previously created. The plans for Postgres 11 and 12 report Buffers: shared hit=641 while
Postgres 13 reports Buffers: shared hit=199: a -69% reduction.
EXPLAIN (ANALYZE, BUFFERS)
SELECT *
FROM osm.building_polygon
WHERE building = 'house'
;
Looking closely at the planning and execution times shows Postgres 13 was only marginally faster. The row counts and index sizes in this case are small enough that the reduction in size does not provide a major impact on overall performance. Reducing the number of blocks Postgres needs to process will provide all sorts of boosts to performance, a little here, a little there. As indexes scale into the range of GB (instead of low MB) the reduction in index size is likely to have a significant positive impact on performance. This will be especially true as index size reaches and exceeds available RAM.
Summary
Postgres 13 is another solid release in a long line of reliable software. In each case I've tested so far it performs better than Postgres 12. I haven't scheduled the upgrade of our production servers yet, though at this point it is only a matter of time!
Thank you to everyone who had a hand -- big or small -- in helping Postgres 13 become yet another great version of our favorite database!
Need help with your PostgreSQL servers or databases? Contact us to start the conversation!
 Mastodon
Mastodon