
Updated for 2020: Load OpenStreetMap data to PostGIS
I originally wrote about how to load OpenStreetMap data into PostGIS just under one year ago. Between then and now, 364 days, a number of major changes have occurred in the form of new versions of all the software involved. Due to the combination of changes I decided to write an updated version of the post. After all, I was no longer able to copy/paste my own post as part of my procedures!
Update, January 2, 2021: This post documents the original "pgsql" output of osm2pgsql. I am no longer using this method for my OpenStreetMap data in PostGIS. The new osm2pgsql Flex output and PgOSM-Flex project provides a superior experience and improved final quality of data.
The goal of this post is to cover the typical machine and configuration I use to load OpenStreetMap data into PostGIS with the latest versions. The first part of the post covers the how of setting up and loading OpenStreetMap data to PostGIS. The second portion explains a bit of the reasoning of why I do things this way. The latest versions of the software at this time are:
- PostgreSQL 12
- PostGIS 3
- osm2pgsql 1.2
This post is part of the series PostgreSQL: From Idea to Database. Also, see our recorded session Load PostGIS with osm2pgsql for similar content in video format.
Changes to software
PostgreSQL 12, PostGIS 3, and osm2pgsql 1.2 are all new releases since the original post. The original used Postgres 11, PostGIS 2.5 and osm2pgsql 0.94. If you just look at the version numbers they may look like small increases, but the whole package is chock-full of improvements!
If you can upgrade to the latest and greatest, I recommend you do so!
While these changes are a major net positive, Postgres 12 and osm2pgsql both have changes to configurations and options that affect this process' performance. While PostGIS 3 is a major upgrade over 2.5, I haven't noticed any changes affecting this process and will not be discussed further here.
The osm2pgsql project released v1.0 in August 2019, marking a major shift
(internally) from the pre-1.0 versions. Then v1.2 was released in
October 2019 to fix a memory error. I won't pretend to know
all the changes that were included with the 1.0 and 1.2 versions, though one of the most noticeable to me
was the removal of the --unlogged switch. This release didn't remove
the functionality, instead it made the
switch unnecessary by making the functionality transparent
when using the --slim --drop switches.
PostgreSQL 12 was released in October 2019 and also has a few changes worth noting. One such change is the overhaul of the storage layer that seems to have negatively impacted performance of bulk loading data. On the other hand, GIST index creation has been sped up and considering GIST creation accounts for more than 50% of the processing time of osm2pgsql that is a big deal too! I wrote about this briefly in my initial review of Postgres 12 and PostGIS 3. Other relevant changes in Postgres 12 are discussed below.
Test machine
The test machine for this was a Digital Ocean droplet with 8 cores and 32 GB RAM (currently $160/month, $0.238/hour) running Ubuntu 18.04 Bionic Beaver. This is the same hardware as "Rig C" used in our recent post Scaling osm2pgsql: Process and costs. The server was configured with a 4GB SWAP file (+25% over RAM).
This is a more powerful server than I used last year, it has double the number of cores (8), 4X the RAM (32GB) and DO's SSDs are super-fast!
Nice! 🤓
— RustProof Labs (@RustProofLabs) October 15, 2019
Data load on a memory optimized droplet @digitalocean #osm2pgsql #gischat @PostgreSQL pic.twitter.com/d9piOiYDoA
PostgreSQL Server
PostgreSQL 12.1 and PostGIS 3.0 were used for testing.
The Postgres instance we are loading data into is for temporary purposes only.
Once the OSM data is loaded I further filter and transform it
(see our PgOSM project)
before being dumped (pg_dump or other) for quick and easy restoration into your other dev and production PostgreSQL instances. This is not the common way of doing things for
OSM tile servers, but my purpose is having data in a proper, relational
database format suitable for analysis. The standard source OSM format
is semi-structured, has NULL values everywhere and is terribly
unproductive for anyone used to proper relational data structures.
The OpenStreetMap data format seems to work for the main OSM projects. The semi-structured key/value tagging is advantageous to provide the flexibility this global project needs... it is just not ideal for analytical/reporting purposes.
Configuration
For the best osm2pgsql performance, the PostgreSQL instance should
be configured differently than a typical, production PostgreSQL server.
The changes I make to postgresql.conf are intended to improve
performance with a focus on reducing disk I/O.
These changes from defaults:
- minimize WAL activity
- disable replication
- increasing checkpoint timeout
- minimize logging
- Sets # Parallel workers =
(# CPU / 2) - 1 - Shared buffers = 25% total RAM
wal_level=minimal
hot_standby=off
max_wal_senders=0
checkpoint_timeout=1d
checkpoint_completion_target=0.90
shared_buffers=8GB
max_parallel_workers_per_gather=3
jit=off
max_wal_size=10GB
min_wal_size=1GB
Don't forget to restart PostgreSQL after changing these settings.
The "why" behind these changes is discussed toward the end under Configuration Notes.
Automate configuration
The method of using disposable database servers is feasible only with automation. I use Ansible to make this a painless, easy process. Automation for deployment and configuration makes testing various configurations on your hardware (or in the cloud) a breeze!
Create Database with PostGIS
With Postgres configured, we need a database to load the OSM data into.
Switch to the postgres user for the remainder of the commands.
sudo su - postgres
Create a database named pgosm.
psql -c "CREATE DATABASE pgosm;"
The PostGIS extension is required, the hstore option is recommended.
psql -d pgosm -c "CREATE EXTENSION IF NOT EXISTS postgis; "
psql -d pgosm -c "CREATE EXTENSION IF NOT EXISTS hstore; "
Data to load
For my testing I used the U.S. West region downloaded Geofabrik on 1/3/2020. The U.S. West PBF file was 1.7 GB. Don't forget, these PBF files are extremely compressed and will take up far more space in PostGIS. The post on scaling this process goes further into depth on the topic.
Still as the postgres user, create a ~/tmp directory and download the source file.
mkdir ~/tmp
cd ~/tmp
wget https://download.geofabrik.de/north-america/us-west-latest.osm.pbf
Installing osm2pgsql
The best way I know to use the latest version of osm2pgsql is to install from source. The osm2pgsql project page has instructions for installing from source.
Ansible (or your automation tool of choice!) should automate this step for you too!
Check to ensure you are using version 1.2 or later.
postgres@user:~$ osm2pgsql --version
osm2pgsql version 1.2.0 (64 bit id space)
Compiled using the following library versions:
Libosmium 2.15.4
Lua 5.2.4
Running osm2pgsql
With the OSM data downloaded and osm2pgsql installed, it is time to run osm2pgsql. I like to double check key Postgres configuration changes
before running. From within psql:
SHOW jit;
jit
-----
off
And:
SHOW max_parallel_workers_per_gather;
max_parallel_workers_per_gather
---------------------------------
3
The following command is what I use to run osm2pgsql. The final portion
pipes the output to a log file with &>. The & at
the end sets us up to disown the process, allowing us to safely disconnect
from the terminal without killing the load process. For this server and
the configuration provided, this should take about 15 minutes.
If you chose to omit installing the HSTORE extension earlier, omit
the --hstore switch here.
postgres@host:~/tmp$ osm2pgsql --create --slim --drop \
--cache 24000 \
--hstore --multi-geometry \
--flat-nodes ~/tmp/nodes \
-d pgosm ~/tmp/us-west-latest.osm.pbf &> ~/load-us-west.log &
postgres@host:~/tmp$ disown
Previous testing with this hardware using Postgres 11, PostGIS 2.5 and osm2pgsql 1.0 took more than 19 minutes. This means it is roughly 15-20% faster to load data using the latest and greatest versions!
osm2pgsql output
You can monitor the processing while it runs using tail, cat or
other tools.
The first block of output goes very fast until it reaches the line
starting with
"Processing:". This is the step where osm2pgsql decompresses the data
from the PBF file and pushes it into PostGIS. There is a lot more
magic than that going on inside, but that's deep enough for this post.
postgres@host:~/tmp$ tail -f ~/load-us-west.log
osm2pgsql version 1.2.0 (64 bit id space)
Allocating memory for dense node cache
Allocating dense node cache in one big chunk
Allocating memory for sparse node cache
Sharing dense sparse
Node-cache: cache=24000MB, maxblocks=384000*65536, allocation method=11
Mid: loading persistent node cache from /var/lib/postgresql/tmp/nodes
Mid: pgsql, cache=24000
Setting up table: planet_osm_nodes
Setting up table: planet_osm_ways
Setting up table: planet_osm_rels
Using built-in tag processing pipeline
Using projection SRS 3857 (Spherical Mercator)
Setting up table: planet_osm_point
Setting up table: planet_osm_line
Setting up table: planet_osm_polygon
Setting up table: planet_osm_roads
Reading in file: /var/lib/postgresql/tmp/us-west-latest.osm.pbf
Using PBF parser.
Processing: Node(227882k 1999.0k/s) Way(18899k 71.05k/s) Relation(179650 1484.71/s) parse time: 501s
Note: The Processing line shown above is from the final output. During the processing, this output will update every few seconds with live stats. It is good to get friendly with htop, iotop, and other monitoring tools during this process too!
Roughly 40% of the total load time is spent with the processing line updating. Once it completes, the processing stats are broken out with total counts and times for processing.
Node stats: total(227882329), max(7103219090) in 114s
Way stats: total(18899481), max(760397427) in 266s
Relation stats: total(181747), max(10529425) in 121s
With the initial load to the database complete, it is all about Postgres/PostGIS processing. This takes longer than the previous stage.
Stopping table: planet_osm_nodes
Stopped table: planet_osm_nodes in 0s
Stopping table: planet_osm_ways
Stopped table: planet_osm_ways in 0s
Stopping table: planet_osm_rels
Stopped table: planet_osm_rels in 0s
Sorting data and creating indexes for planet_osm_point
Sorting data and creating indexes for planet_osm_line
Sorting data and creating indexes for planet_osm_polygon
Sorting data and creating indexes for planet_osm_roads
Copying planet_osm_roads to cluster by geometry finished
Creating geometry index on planet_osm_roads
Creating indexes on planet_osm_roads finished
All indexes on planet_osm_roads created in 21s
Completed planet_osm_roads
Copying planet_osm_point to cluster by geometry finished
Creating geometry index on planet_osm_point
Creating indexes on planet_osm_point finished
All indexes on planet_osm_point created in 98s
Completed planet_osm_point
Copying planet_osm_line to cluster by geometry finished
Creating geometry index on planet_osm_line
Copying planet_osm_polygon to cluster by geometry finished
Creating geometry index on planet_osm_polygon
Creating indexes on planet_osm_line finished
All indexes on planet_osm_line created in 257s
Completed planet_osm_line
Creating indexes on planet_osm_polygon finished
All indexes on planet_osm_polygon created in 349s
Completed planet_osm_polygon
Osm2pgsql took 852s overall
Mid: removing persistent node cache at /var/lib/postgresql/tmp/nodes
node cache: stored: 227882329(100.00%), storage efficiency: 56.17% (dense blocks: 14666, sparse nodes: 142785045), hit rate: 100.00%
Configuration notes
The following sections detail my reasoning for the above recommendations. If you aren't interested with the why behind the above feel free to skip to the summary.
Postgres: Parallel Worker performance
The default value for max_parallel_workers_per_gather
has been set to 2 since Postgres 10.
With Postgres 12, PostGIS is finally able to utilize parallel query.
This is fantastic news! That said, just being able to
use parallel query does not mean it will necessarily be faster.
That left me to find the new sweet spot with configuring parallel query
for osm2pgsql.
max_parallel_workers_per_gather = (# of cores / 2) - 1
This formula has held for me through hundreds of osm2pgsql tests with quad core up through 16 core servers, and data sizes ranging from under 1GB (Colorado) through more than 20GB (Europe). This sweet spot generally provides 20-25% faster load times over disabling parallel query. I did find some combinations of power and data size where another configuration worked better, but that will always be the case with generalized advice like this.
The following chart shows the average times for loading U.S. West on this server with various configurations for parallel query.
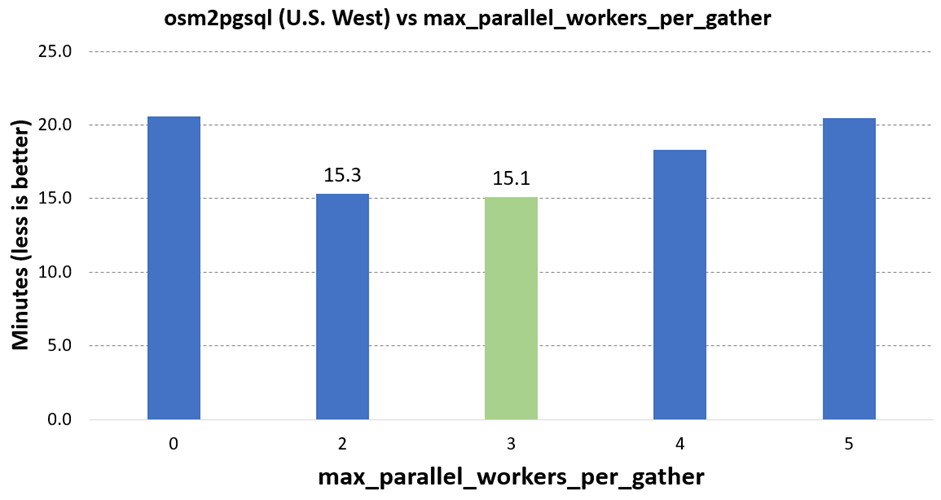
There have been some edge-case reports where parallel processing greatly
slowed down osm2pgsql.
If you think you are experiencing a performance hit with parallel workers,
set max_parallel_workers_per_gather=0 to disable the feature to verify.
See PostgreSQL 10 Parallel Queries and Performance for more generalized details (non-PostGIS) about parallel query in Postgres.
Postgres: JIT
There is one important change to note in the default configuration
of Postgres 12 (postgresql.conf).
JIT (Just In Time)
is now set to on by default, instead of off. I am disabling
JIT on our servers by default for a couple reasons. First, I did some
informal performance testing of JIT on our workloads and found
no benefit to having JIT enabled. That alone wasn't enough
for me to disable the feature though. It was the discovery that
osm2pgsql performance can be severely impacted by JIT.
There's an issue reported in the
osm2pgsql project
and with Postgres project.
I won't dive into those details further in this post.
osm2pgsql flat nodes
In my prior post I recommended avoiding --flat-nodes for PBF files under
roughly 15GB. That advice is likely still true if you are using slower
spinning disk HDDs. With much faster SSDs, I have found the cutoff point
around 1-2 GB. The U.S. West file is just under 2GB and running with
flat nodes is about 13% faster than running without flat nodes.
The larger the data set, the greater the benefit from this option (though increasing RAM is even better!).
I tested load performance fpr the North America region (8.9GB) and
found it loads nearly 25% faster when using --flat-nodes vs. without.
Again, fast I/O is the key!
The side effect of flat nodes is the ever growing nodes file it needs to use. Last January the file clocked in at 46GB, as of now it is up to 53GB. That shows 15% growth in one year. It will continue to grow in size as the overall OSM database grows larger.
osm2pgsql cache
--cache 24000 sets the process to cache 24GB, or 75% of total system RAM per their Wiki. I haven't spent much time testing the effect of this in osm2pgsql 1.2, but when I tested it in v1.0 I did not find much benefit or detriment to fiddling with this value other than at the extremes.
This memory is independent of RAM that PostgreSQL will use. You can
be conservative with this setting if you want to opt on the
side of stability, especially with Postgres' shared_buffers being
given the other 25%!
I haven't had issues with this with the inclusion of the SWAP file
mentioned previously.
Summary
In this post I covered the updated and improved steps I use to load OpenStreetMap data into PostGIS using osm2pgsql. The difference in osm2pgsql tools before and after the 1.0 release is noticeable, the changes seem to be moving the project in a good direction. The Postgres 12 release also added its own new nuances: parallel query works with PostGIS (yay!), but be careful with JIT and parallel query.
The best part of all of this? I can load data faster than ever before, while also taking advantage of new features! 🤓
Need help with your PostgreSQL servers or databases? Contact us to start the conversation!
 Mastodon
Mastodon