
PostgreSQL 13Beta3: B-Tree index deduplication
PostgreSQL 13 development is coming along nicely, Postgres 13 Beta3 was
released on 8/13/2020.
The Postgres Beta 1 and 2 releases were released in May and June 2020.
One of the features that has my interest in Postgres 13 is the B-Tree deduplication effort. B-Tree indexes are the default indexing method
in Postgres, and are likely the most-used indexes in production
environments.
Any improvements to this part of the database are likely to have wide-reaching benefits.
Removing duplication from indexes keeps their physical size smaller,
reduces I/O overhead, and should help keep SELECT queries fast!
This post is part of the series PostgreSQL: From Idea to Database.
There is a good summary of the what and how of this improvement
in Laurenz Albe's post from early in June 2020, presumably using
Pg13 Beta1. Hamid Akhtar's post in July
covered this feature using Pg13 Beta2 and a different approach including
a look at the performance using EXPLAIN.
This post takes yet another look at this improvement using Pg13 Beta3.
I intend to see how well this improvement pans out on a data set I use in production. For that task my go-to is
OpenStreetMap data loaded to Postgres/PostGIS using osm2pgsql.
Install Postgres 13 Beta 3
The first step is to install the two versions of Postgres (12 and 13beta3)
on a single Ubuntu 18 host. In the past when I have tested pre-production
releases I have built Postgres from source instead of using apt.
This time around I decided to use apt install, so am including the
basic process for that.
The advised way to install PostgreSQL is from the pgdg (PostgreSQL Global Development Group) repositories,
see the Postgres wiki for more.
To enable the beta versions, the line needed in /etc/apt/sources.list.d/pgdg.list is:
deb http://apt.postgresql.org/pub/repos/apt/bionic-pgdg main 13
With that in place, update the sources and install Postgres and PostGIS.
sudo apt update
# Postgres 12
sudo apt install postgresql-12 postgresql-12-postgis-3
# Postgres 13 (Currently Beta)
sudo apt install postgresql-13 postgresql-13-postgis-3
On Ubuntu, installing multiple versions will create multiple instances running on different ports. The test server I'm using to write this post
currently has three versions of Postgres installed, only two are currently running. Postgres 12 was installed first so "won" the default port of 5432. Postgres 11 was installed second and was assigned 5433, and Pg13 beta 3 was installed last and was assigned port 5434. The pg_lsclusters is avaiable on Debian/Ubuntu hosts as part of the wrapper around pg_ctl.
sudo -u postgres pg_lsclusters
Ver Cluster Port Status Owner Data directory Log file
11 main 5433 down postgres /var/lib/postgresql/11/main /var/log/postgresql/postgresql-11-main.log
12 main 5432 online postgres /var/lib/postgresql/12/main /var/log/postgresql/postgresql-12-main.log
13 main 5434 online postgres /var/lib/postgresql/13/main /var/log/postgresql/postgresql-13-main.log
This post does not use Postgres 11 beyond this example.
When working with multiple versions installed it is helpful to verify versions match what you expect them to be. First, the port 5432 for Postgres 12 version.
psql -d pgosm -p 5432 -c "select version();"
┌──────────────────────────────────────────────────────────────────────────────┐
│ version │
╞══════════════════════════════════════════════════════════════════════════════╡
│ PostgreSQL 12.4 (Ubuntu 12.4-1.pgdg18.04+1) on x86_64-pc-linux-gnu, compiled…│
│… by gcc (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0, 64-bit │
└──────────────────────────────────────────────────────────────────────────────┘
Now, port 5434 for Postgres 13 version.
psql -d pgosm -p 5434 -c "select version();"
┌──────────────────────────────────────────────────────────────────────────────┐
│ version │
╞══════════════════════════════════════════════════════════════════════════════╡
│ PostgreSQL 13beta3 (Ubuntu 13~beta3-1.pgdg18.04+1) on x86_64-pc-linux-gnu, c…│
│…ompiled by gcc (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0, 64-bit │
└──────────────────────────────────────────────────────────────────────────────┘
Create Indexes
Both versions of Postgres were loaded with the same Colorado OpenStreetMap
data loaded using osm2pgsql.
The osm2pgsql does not create any B-Tree indexes on its own, only the GIST
indexes on geometries.
For this post, we examine B-Tree index sizes created on four columns:
osm_id, highway, waterway, and natural.
Looking at the stats on the public.planet_osm_line table I can make
a couple guesses where we will and will not see gains based on n_distinct.
I can guess we will not see major gains in the
osm_id, there is only a small amount of duplication in those values.
The other three columns (highway, natural and waterway) have a small number of distinct values
and varying amounts of NULL values. These three columns would all
be candidates for partial indexes to avoid indexing the NULL values,
thus reducing the size of the created index.
I have hopes to see the benefits in Postgres 13 on these columns, possibly
making the use of partial indexes less frequent.
SELECT attname, n_distinct, null_frac
FROM pg_catalog.pg_stats
WHERE tablename = 'planet_osm_line'
AND attname IN ('osm_id', 'highway', 'waterway', 'natural')
;
┌──────────┬────────────┬────────────┐
│ attname │ n_distinct │ null_frac │
╞══════════╪════════════╪════════════╡
│ osm_id │ -0.833553 │ 0 │
│ highway │ 26 │ 0.41616666 │
│ natural │ 4 │ 0.994 │
│ waterway │ 9 │ 0.6663 │
└──────────┴────────────┴────────────┘
Index on osm_id
First up is the osm_id column, a nearly unique set of positive and
negative values. The index to create in both versions:
CREATE INDEX ix_osm_line_osm_id ON public.planet_osm_line (osm_id);
The following query is used throughout to report out index sizes. The query itself will not be repeated, as only the filter would change.
SELECT ai.schemaname AS s_name, ai.relname AS t_name,
ai.indexrelname AS index_name,
pg_size_pretty(pg_relation_size(quote_ident(ai.schemaname)::text || '.' || quote_ident(ai.indexrelname)::text)) AS index_size,
pg_relation_size(quote_ident(ai.schemaname)::text || '.' || quote_ident(ai.indexrelname)::text) AS index_size_bytes
FROM pg_catalog.pg_stat_all_indexes ai
WHERE ai.indexrelname LIKE 'ix_osm_line%'
ORDER BY index_name
;
Due to the low number of duplicates, it is no surprise that the
show only a tiny reduction in the size. The reduction
would not be detectable from only the index_size column (in MB), the
index_size_bytes shows the slight reduction in size (29,515,776 bytes vs. 29,384,704 bytes).
Pg 12.
┌─[ RECORD 1 ]─────┬────────────────────┐
│ s_name │ public │
│ t_name │ planet_osm_line │
│ index_name │ ix_osm_line_osm_id │
│ index_size │ 28 MB │
│ index_size_bytes │ 29515776 │
└──────────────────┴────────────────────┘
Pg 13.
┌─[ RECORD 1 ]─────┬────────────────────┐
│ s_name │ public │
│ t_name │ planet_osm_line │
│ index_name │ ix_osm_line_osm_id │
│ index_size │ 28 MB │
│ index_size_bytes │ 29384704 │
└──────────────────┴────────────────────┘
Index on highway
The highway data in the planet_osm_line data is a good example of when
a
partial index
might typically be a good idea to minimize index size. My hunch (and hope)
is that the de-duplication will make a partial index here a moot point by reducing the size required to index a large number of NULL values.
Create two indexes, one partial covering the non-NULL values and one full
index on the entire table.
CREATE INDEX ix_osm_line_highway_partial
ON public.planet_osm_line (highway)
WHERE highway IS NOT NULL;
CREATE INDEX ix_osm_line_highway_full
ON public.planet_osm_line (highway);
The two indexes in Postgres 12, notice the partial index cuts out about 1/3 of the size from the full index.
┌────────┬─────────────────┬─────────────────────────────┬────────────┐
│ s_name │ t_name │ index_name │ index_size │
╞════════╪═════════════════╪═════════════════════════════╪════════════╡
│ public │ planet_osm_line │ ix_osm_line_highway_full │ 30 MB │
│ public │ planet_osm_line │ ix_osm_line_highway_partial │ 19 MB │
└────────┴─────────────────┴─────────────────────────────┴────────────┘
Now looking at the same two indexes in Postgres 13, and WOW! The full index in Postgres 13 is roughly half the size of the partial index in Postgres 12!! With this type of savings in size, I do not expect that I will bother with the partial index anywhere near as often.
┌────────┬─────────────────┬─────────────────────────────┬────────────┐
│ s_name │ t_name │ index_name │ index_size │
╞════════╪═════════════════╪═════════════════════════════╪════════════╡
│ public │ planet_osm_line │ ix_osm_line_highway_full │ 8944 kB │
│ public │ planet_osm_line │ ix_osm_line_highway_partial │ 5272 kB │
└────────┴─────────────────┴─────────────────────────────┴────────────┘
I do not expect this improvement alone will remove the need for partial indexes. Instead, it will reduce the need for partial indexes to a smaller subset of edge cases. Partial indexes will still be a useful tool.
Indexes on waterway and natural
The final two columns to test have different unique and null ratios than the highway column. Create the indexes.
CREATE INDEX ix_osm_line_waterway_partial
ON public.planet_osm_line (waterway)
WHERE waterway IS NOT NULL;
CREATE INDEX ix_osm_line_waterway_full
ON public.planet_osm_line (waterway);
CREATE INDEX ix_osm_line_natural_partial
ON public.planet_osm_line ("natural")
WHERE "natural" IS NOT NULL;
CREATE INDEX ix_osm_line_natural_full
ON public.planet_osm_line ("natural");
Note: osm2pgsql creates the
naturalcolumn, a reserved keyword in SQL. You must use double quotes to reference this column, e.g.SELECT "natural" ...
Below are the index sizes for these four (4) new indexes in Postgres 12.
The partial index on the natural column has serious win over the full index here due to 99.4% of the rows being NULL. The waterways also
saw a bigger savings on the partial index, with 67% of rows being NULL.
For reference, the highways column was 42% NULL.
┌────────┬─────────────────┬──────────────────────────────┬────────────┐
│ s_name │ t_name │ index_name │ index_size │
╞════════╪═════════════════╪══════════════════════════════╪════════════╡
│ public │ planet_osm_line │ ix_osm_line_natural_full │ 28 MB │
│ public │ planet_osm_line │ ix_osm_line_natural_partial │ 264 kB │
│ public │ planet_osm_line │ ix_osm_line_waterway_full │ 28 MB │
│ public │ planet_osm_line │ ix_osm_line_waterway_partial │ 9680 kB │
└────────┴─────────────────┴──────────────────────────────┴────────────┘
Again, each index in Postgres 13 is smaller than its Postgres 12
counterpart by significant amounts. The wins here have shifted a bit with
the different pattern of NULL values.
┌────────┬─────────────────┬──────────────────────────────┬────────────┐
│ s_name │ t_name │ index_name │ index_size │
╞════════╪═════════════════╪══════════════════════════════╪════════════╡
│ public │ planet_osm_line │ ix_osm_line_natural_full │ 8912 kB │
│ public │ planet_osm_line │ ix_osm_line_natural_partial │ 80 kB │
│ public │ planet_osm_line │ ix_osm_line_waterway_full │ 8912 kB │
│ public │ planet_osm_line │ ix_osm_line_waterway_partial │ 2968 kB │
└────────┴─────────────────┴──────────────────────────────┴────────────┘
TLDR;
Postgres 13's B-Tree de-duplication is a serious win for indexes on columns
with significantly duplicated values. The columns I tested with duplication
and NULL values saw reductions in size of 69-72%.
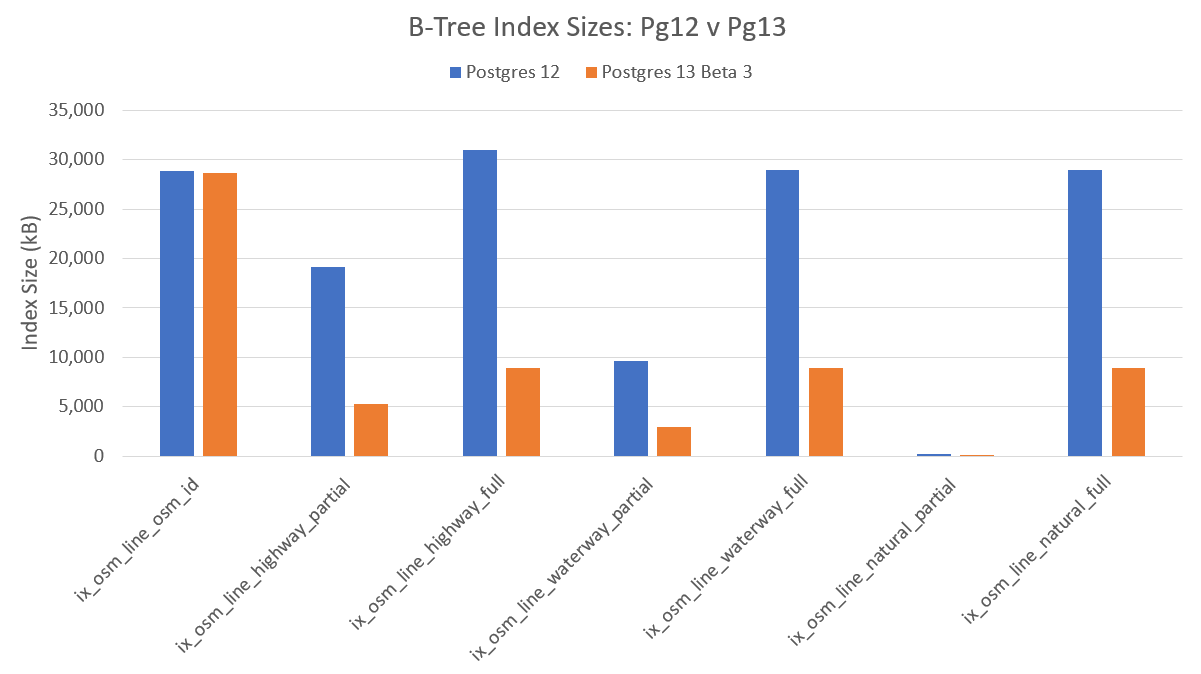
The following table pulls the results of all the tests above together.
| Index Name | Postgres 12 size (kB) | Postgres 13 Beta 3 size (kB) | % Reduction |
|---|---|---|---|
| ix_osm_line_osm_id | 28,824 | 28,696 | 0.4% |
| ix_osm_line_highway_partial | 19,096 | 5,272 | 72.4% |
| ix_osm_line_highway_full | 31,024 | 8,944 | 71.2% |
| ix_osm_line_waterway_partial | 9,680 | 2,968 | 69.3% |
| ix_osm_line_waterway_full | 28,968 | 8,912 | 69.2% |
| ix_osm_line_natural_partial | 264 | 80 | 69.7% |
| ix_osm_line_natural_full | 28,920 | 8,912 | 69.2% |
The same data is below in two charts. First, the chart showing the percentage of reduction in size.
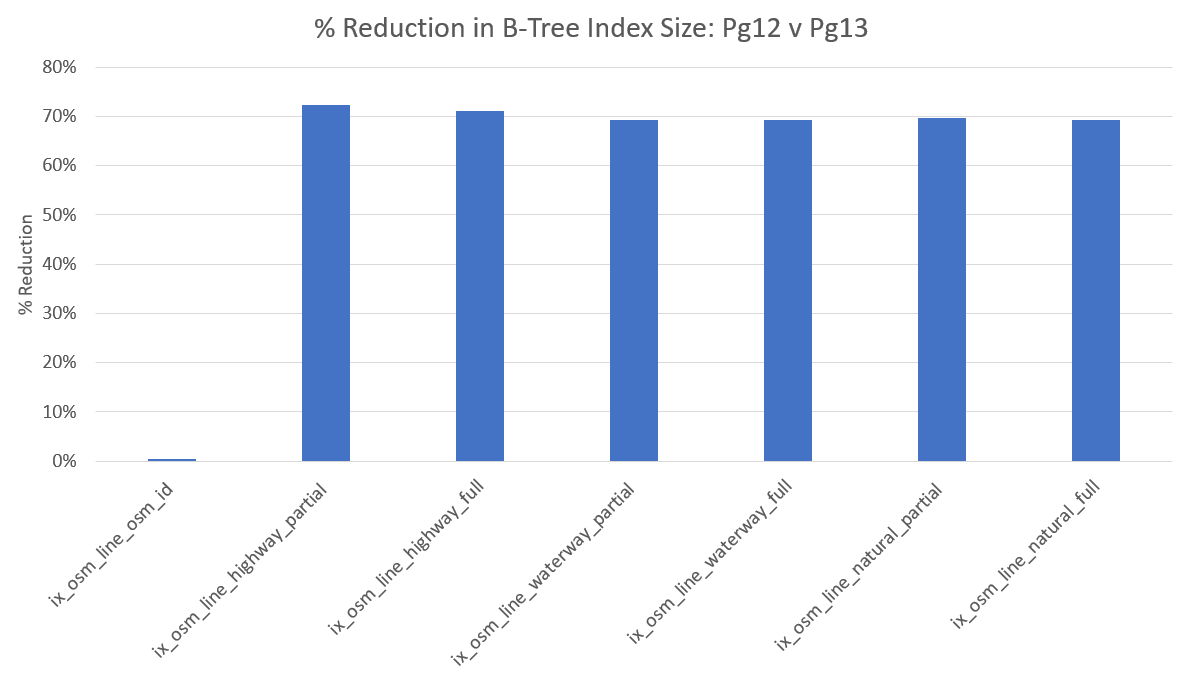
The following chart shows the size comparisons for each index tested, in kilobytes (kB).
Summary
PostgreSQL 13's B-Tree deduplication might be my favorite thing about
the upcoming release so far. I am quite impressed by the amount of
savings on disk this improvement has achieved. It won't help
with unique B-Tree index size, though there are plenty of non-unique
indexes similar to what was shown here. The ability to create
more compact indexes on columns with NULL values, without requiring
partial indexes, is another benefit. It seems this will make it
easier to get the right index while keeping index size small.
Need help with your PostgreSQL servers or databases? Contact us to start the conversation!
 Mastodon
Mastodon