
See you at PASS Data Community Summit!
This year's PASS summit in Seattle is only four weeks away! I am honored that I was selected to provide a full day pre-conference training on PostGIS, as well as a general session talk on extensions. Both of my topics are focused on the Postgres ecosystem. Of course, that is not a surprise to my regular readers! It may be a surprise to those who have been aware of PASS in the past.
What is PASS?
This year's PASS conference is called "PASS Data Community Summit 2023." In the past, PASS was an acronym for Professional Association for SQL Server, and the conference was very much a Microsoft conference. When I attended in 2018 it was because I wanted to learn more about MS SQL Server and PowerBI. This year, that focus is expanding to include Postgres!
Geocode Addresses with PostGIS and Tiger/LINE
My previous post, Setup Geocoder with PostGIS and Tiger/LINE, prepared a PostGIS geocoder with TIGER/Line data for Colorado. This post uses that setup to bulk geocode addresses from OpenStreetMap buildings to try to determine the accuracy of the geometry data derived from the input addresses.
Quality Expectations
Let's get this out of the way: No geocoding process is going to be perfectly accurate.
There are a variety of contributing factors to the data quality. The geocoder data source is pretty decent, coming from the U.S. Census Bureau's TIGER/Line data set. The vintage is 2022, and this is as recent as I can load today using this data source. We should to understand that this will not contain any new development or changes from the past year (or so).
The OpenStreetMap data is also a source of error. It is certain that there are typos, outdated addresses, and other inaccuracies from the OpenStreetMap data. Some degree of that has to be expected with nearly any data source. The region of OpenStreetMap used will also be an influence, some regions just don't have many boots-on-the-ground editing and validating OpenStreetMap data.
Setup Geocoder with PostGIS and Tiger/LINE
Geocoding addresses is the process of taking a street address and converting it to its location on a map. This post shows how to create a PostGIS geocoder using the U.S. Census Bureau's TIGER/Line data set. This is part one of a series of posts exploring geocoding addresses. The next post illustrates how to geocode in bulk with a focus on evaluating the accuracy of the resulting geometry data.
Before diving in, let's look at an example of geocoding.
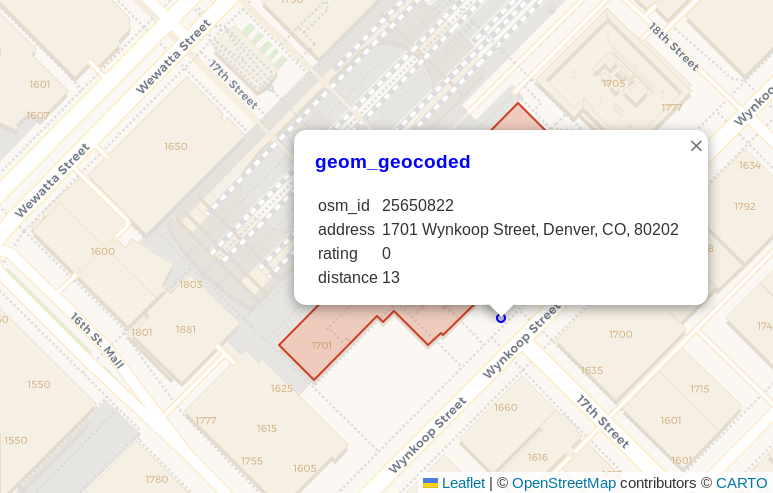
The address for Union Station
(see on OpenStreetMap)
is 1701 Wynkoop Street, Denver, CO, 80202.
This address was the input to geocode.
The blue point shown in the following screenshot
is the resulting point from the
PostGIS geocode()
function. The pop-up dialog shows the address, a rating of 0,
and the calculated distance away from the OpenStreetMap polygon representing that address (13 meters), shown in red under the pop-up
dialog.
PostgreSQL 16 improves infinity: PgSQLPhriday #012
This month's #pgsqlphriday challenge is the 12th PgSQL Phriday, marking the end of the first year of the event! Before getting into this month's topic I want to give a shout out to Ryan Booz for starting #pgsqlphriday. More importantly though, a huge thank you to the hosts and contributors from the past year! I looked forward to seeing the topic each month followed by waiting to see who all would contribute and how they would approach the topic.
Check out pgsqlphriday.com for the full list of topics, including recaps from each topic to link to contributing posts. This month is the 7th topic I've been able to contribute to the event. I even had the honor of hosting #005 with the topic Is your data relational? I'm really looking forward to another year ahead!
Now returning to your regularly scheduled PgSQL Phriday content.
This month, Ryan Booz chose the topic: What Excites You About PostgreSQL 16? With the release of Postgres 16 expected in the near(ish) future, it's starting to get real. It won't be long until casual users are upgrading their Postgres instances. To decide what to write about I headed to the Postgres 16 release notes to scan through the documents. Through all of the items, I picked this item attributed to Vik Fearing.
- Accept the spelling "+infinity" in datetime input
The rest of this post looks at what this means, and why I think this matters.
Load the Right Amount of OpenStreetMap Data
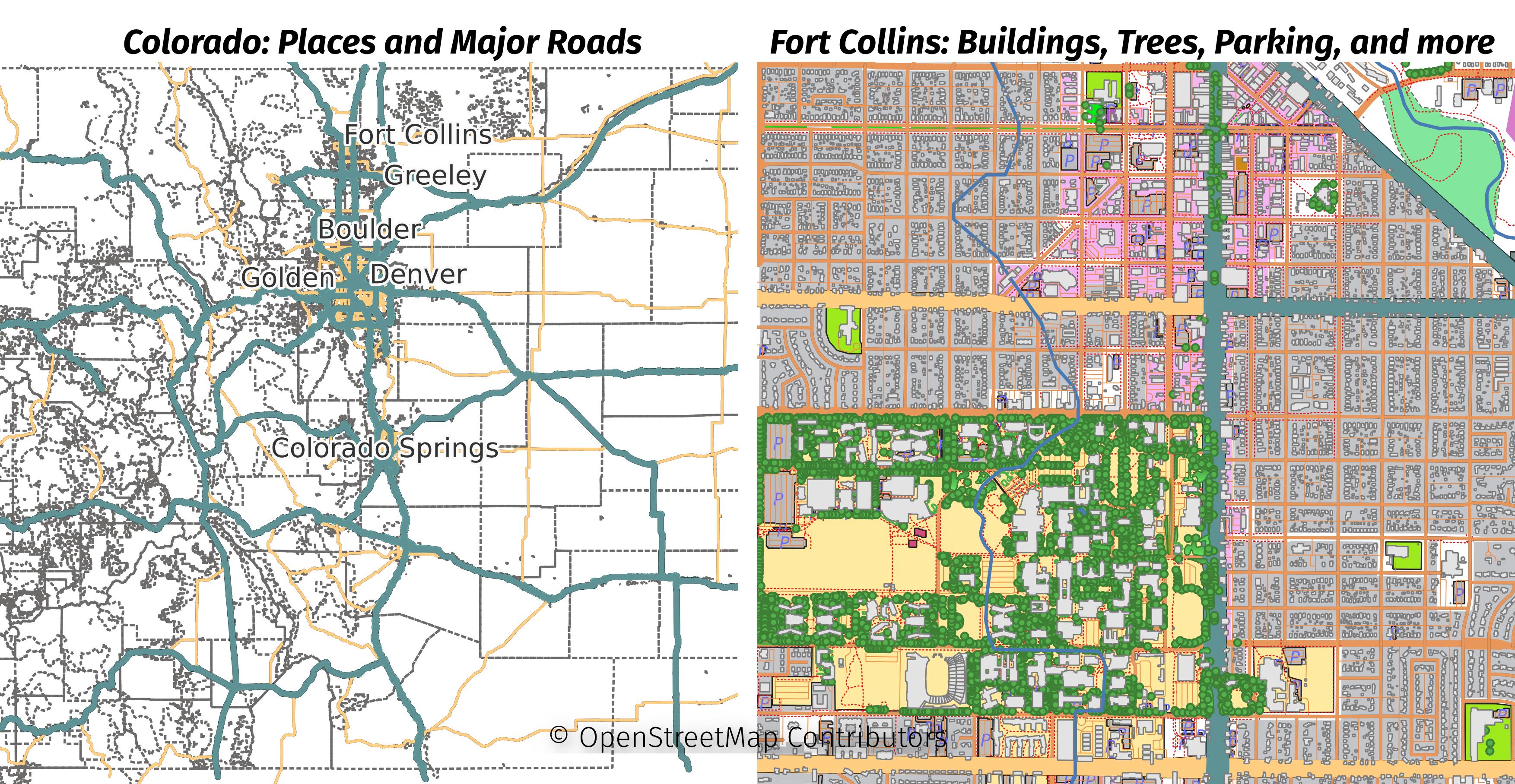
Populating a PostGIS database with OpenStreetMap data is favorite way to start a new geospatial project. Loading a region of OpenStreetMap data enables you with data ranging from roads, buildings, water features, amenities, and so much more! The breadth and bulk of data is great, but it can turn into a hinderance especially for projects focused on smaller regions. This post explores how to use PgOSM Flex with custom layersets, multiple schemas, and osmium. The goal is load limited data for a larger region, while loading detailed data for a smaller, target region.
The larger region for this post will be the Colorado extract from Geofabrik. The smaller region will be the Fort Collins area, extracted from the Colorado file. The following image shows the data loaded in this post with two maps side-by-side. The minimal data loaded for all of Colorado is shown on the left and the full details of Fort Collins is on the right.
 Mastodon
Mastodon