
Load OpenStreetMap data to PostGIS
PostGIS rocks, and OpenStreetMap is Maptastic! One challenge I've had with this open source pair, though, has been getting a good, comprehensive set of OSM data into Postgres, on non-enterprise hardware. A few years ago I found Geofabrik's download server... a lifesaver! They offer logical regional exports of OpenStreetMap data, updated daily, distributed by a number of regional levels. The one I use the most is the U.S. state-level files, namely Colorado.
Once I had found this stellar data set (updated daily!) I wanted a way to easily get my own spatial database
regularly updated with Colorado. One of the commonly mentioned tools is
osm2pgsql.
The problem is, I was (and still am) trying to run processes on the smallest hardware possible and this
process is not exactly lightweight!
PostgreSQL + PostGIS + OpenStreetMap = 100% Open Source, GIS-filled database!
This post documents what has worked for me, including timings for baseline planning.
This post is part of the series PostgreSQL: From Idea to Database.
Test machine
My test machine for this is a virtual machine (VirtualBox). The host machine has a quad-core Intel at 3.6Ghz, 32 GB RAM and a 7200 RPM HDD. The VM was given four (4) of the host's 8 threads, 8 GB of RAM, and a 100 GB dynamically allocated VHD. Both host and guest machines are running Ubuntu 18.04 Bionic Beaver, the host is the desktop version while the guest is the server version.
While this machine was given more power than I typically use for this, I did so because I wanted to test a variety of settings for osm2pgsql, and making things run even slower (with less power) would have greatly increased the time it took to write this post.
PostgreSQL Server
PostgreSQL 11.1 and PostGIS 2.5 were used for testing.
The Postgres instance we are loading data into is for temporary purposes only.
Once the OSM data is loaded, it can (should) be further filtered and/or transformed before being
dumped (pg_dump or other) for quick and easy restoration into your other dev and production PostgreSQL instances.
I recommend loading data from OSM's PBF format into PostGIS in a dedicated, temporary PostgreSQL instance. This instance should not share disks with any production systems! Postgres and osm2pgsql both use a lot of disk (I/O) during this process!
Configuration
The PostgreSQL instance should be configured differently than a typical, production PostgreSQL server.
The changes I make to postgresql.conf are intended to improve performance by reducing disk I/O.
These changes reduce WAL activity, disabling replication, increasing checkpoint timeout, and disables autovacuum.
Warning: Setting
autovacuum=offis a bad idea on most systems! Do not do this on production instances!
wal_level=minimal
hot_standby=off
max_wal_senders=0
checkpoint_timeout=1d
max_wal_size=10GB
min_wal_size=1GB
shared_buffers=500MB
autovacuum=off
WARNING: These settings are for NOT ideal for most production Postgres servers!
The VM I am using has 8GB RAM, so I could set shared_buffers higher if we were just worried about the
database, but we have to give room for osm2pgsql to run too.
Don't forget to restart PostgreSQL after changing these settings.
Database
With Postgres configured, we need a database to load the downloaded OSM data into.
First, switch to the postgres user for the remainder of the commands.
Create a database named pgosm.
psql -d postgres -c "CREATE DATABASE pgosm WITH ENCODING='UTF8';"
The PostGIS extension is required, the hstore option is recommended.
psql -d pgosm -c "CREATE EXTENSION IF NOT EXISTS postgis; "
psql -d pgosm -c "CREATE EXTENSION IF NOT EXISTS hstore; "
Data to load
Using the .osm.pbf (see the OSM Wiki for more on the file format) extracts made available from Geofabrik's download server. For my testing I used the state of Colorado file downloaded on 12/29/2018. The osm.pbf file was 165 MB. Once loaded to PostGIS with spatial (GIST) indexes, it will take nearly 2.5 GB of disk space!
This file should be downloaded on the machine running PostgreSQL, that will also run osm2pgsql. The following
commands will create a tmp directory in your home directory and download the latest Colorado OSM file.
mkdir ~/tmp
cd ~/tmp
wget https://download.geofabrik.de/north-america/us/colorado-latest.osm.pbf
Running osm2pgsql
With the OSM data downloaded, the last step is to get a style used for the import. I've always used
the one available from gravitystorm. These commands clone the repo under a ~/git/ directory.
mkdir ~/git
cd ~/git
git clone https://github.com/gravitystorm/openstreetmap-carto.git
The path used above is needed for the --style flag in the following osm2pgsql command.
The following command is suited for machines down to a single core and 1GB RAM.
osm2pgsql --create --slim --unlogged \
--cache 200 \
--number-processes 1 \
--hstore \
--style ~/git/openstreetmap-carto/openstreetmap-carto.style \
--multi-geometry \
-d pgosm ~/tmp/colorado-latest.osm.pbf
Parameters
The osm2pgsql command has a few parameters to tweak for performance. The first is the filename you want
to load, change as needed, e.g. ~/tmp/colorado-latest.osm.pbf.
The other two parameters are to limit for your system, and balance the main bottleneck
we have to work around: disk I/O. The exact parameters that work best for you will depend on your system.
--cache 200 sets the process to cache 200MB. This is independent of RAM that PostgreSQL will use.
--number-processes 1 sets osm2pgsql to only use one process for loading. If you have multiple processors you can increase this value but effects are limited mostly by available RAM and I/O speed.
For best performance
Add --unlogged flag. This makes osm2pgsql use PostgreSQL's unlogged table option. This nifty feature is perfectly suited for temporary processes! It bypasses writing data the WAL saving all that I/O. I/O is the bottleneck of this process, so every step to reduce I/O is helpful.
Remember, I've already warned you this should be a test server. When using unlogged tables, you need to make sure you take steps to backup your data; unlogged tables are not crash safe.
A note on flat nodes
I've seen examples showing the use of --flat-nodes. Flat nodes should not be used unless you are
loading a full planet, or Europe.
If you're loading a smaller file than Europe (e.g. < 15GB), it will (probably) do bad things
and slow you down. Plenty of places give examples with this command, but don't use it.
See the project docs if you
don't believe me. While the docs in one place mentioned a 23GB file, another place mentioned a >30GB file,
my test with --flat-nodes left a 46 GB nodes file behind.
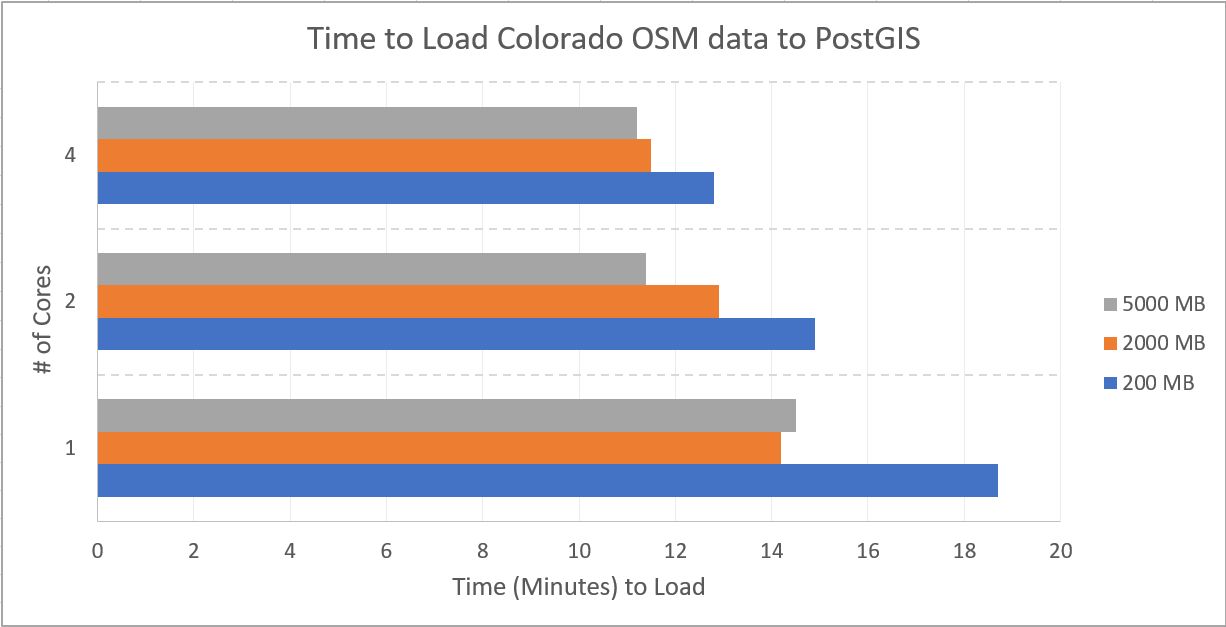
Observations
To help give an idea of how long this process can take, I ran osm2pgsql with 9 combinations of settings controlling RAM and CPU utilization. RAM was set to 200, 2000, and 5000 MB; processes was set to 1, 2 and 4. Each configuration was ran twice, with the average of the two runs being presented.
These timings do not use the --unlogged flag, that option should reduce load times even further.
OSM Data in PostgreSQL
The OSM data is now loaded to Postgres in three (3) main tables named with the prefix planet_osm_.
The last portion of each table name describes the type of data it includes,
point, line, and polygon. The following query shows the row counts in each of the
tables now storing Colorado's OSM data.
SELECT 'point' AS tbl, COUNT(*) AS cnt
FROM public.planet_osm_point
UNION
SELECT 'line', COUNT(*)
FROM public.planet_osm_line
UNION
SELECT 'polygon', COUNT(*)
FROM public.planet_osm_polygon
;
┌─────────┬─────────┐
│ tbl │ cnt │
╞═════════╪═════════╡
│ line │ 1127512 │
│ point │ 586269 │
│ polygon │ 640449 │
└─────────┴─────────┘
The data is loaded, yet the format of stuffing all the data based solely on geometry type (line/point/polygon) leaves quite a bit to be desired. To illustrate why, imagine a single database table that stored products, sales, and employee data all in a single table together. They all have numeric data so why not? The products have prices, sales contain an aggregate of product prices, and employees have a salary or wage... all numeric!
That idea probably seems silly right away because the data is all very different, but that's exactly what an OSM
table that includes all of one type of geometry does. The table public.planet_osm_point includes
stop signs, business locations, trees, and mountain peaks just because they're all points. Yes, but, they quite different representations of data.
My next post, Transform OpenStreetMap data in PostGIS covers more about the structure of these three tables and how to transform them into a set of more usable tables via PgOSM.
References
My main resources for learning and experimenting through this were these sites below. Unfortunately, most are out of date, include broken links, and missing information.
- osm2pgsql repo
- Docs (in repo)
- OSM wiki ("Pages on the OpenStreetMap wiki are known to be unreliable and outdated." - The OpenStreetMap wiki)
- Boston GIS
- volkerschatz.com
- Benchmarks from OSM wiki
Summary
This post has provided a guide on how to load OpenStreetMap data to PostgreSQL/PostGIS using osm2pgsql. While the process itself has a few steep learning curves, once the steps are clearly outlined the process is mostly just a waiting game. The next step, getting the OpenStreetMap data ready for use, is covered in my post next post: PgOSM: Transform OpenStreetMap data in PostGIS.
Need help with your PostgreSQL servers or databases? Contact us to start the conversation!
 Mastodon
Mastodon