
PostgreSQL Load Testing
A recent conversation got me thinking about database performance, specifically PostgreSQL. Well, to be honest, I'm always thinking about databases and their performance. I've pushed PostgreSQL to load 500,000 records per second, compared PostgreSQL to MySQL, and more.
This conversation did make me decide it was time to put one of RustProof Labs' newest PostgreSQL databases to the test. The database is part of a new product we plan to go live with in Spring 2018. Now is the perfect time for us to do a final check of our estimates for how many users this system will be able to handle. If our assumptions were wrong we still have time to adjust.
Preparing for Testing
I've written before about how I define the tests to run for testing performance under load. The first step of load testing is to consider how many users will be using the system at any given time; second is to consider is how those users will interact with the system. It's also good to remember exactly what you're trying to test, and to test the smallest component possible.
In this case I want to test how the database holds up on its most critical and stressful role:
Lots of new data coming in! In our testing, 33% of
database queries are INSERT queries and should be much more stressful on the database than its typical expected load.
This series of testing is intentionally targeted to stress one specific sub-component with unusually high load.
Tools for the Job
The database in question is the PostgreSQL database powering TrackYourGarden.com. For most of the tests we used PostgreSQL 9.5, though tests some used PostgreSQL 9.6. That variation shouldn't have much impact but is worth noting. We mainly tested the database running in AWS using an environment duplication our planned production setup. The other tests were done with PostgreSQL running on a Raspberry Pi 2B+, just for a bit of fun and to prove a personal point.
- PostgreSQL
- Python
- Jupyter
- Ansible
- AWS EC2
- Raspberry Pi 2B+
I used a Jupyter notebook running on one AWS EC2 instance to run the Python-based load testing. It was a simple matter to copy a few dozen lines of code from the application and write a couple dozen more to loop through to simulate queries. All said and done it took about 150 lines of Python code to implement these tests.
This trivial amount of code makes it easy to test a critical component of our application under various loads. This process helps ensure we can plan for the appropriate amount of resources, and spot areas of trouble before they cause our customers to complain.
Code for Tests
The function below handles the task of repeatedly creating new plant records with a set pause between
iterations. Each loop executes three queries simulating (in high speed) what happens each time
one user performs one specific action. The problem with this as it exists
is the program runs in series, meaning that the next loop can't start until the previous loop finishes.
import time
def sim_plant_insert(loops=1000, sleep_delay=1, update_interval=100):
i = 0
start_time = time.time()
while i < loops:
planting_id = get_random_record('ui.get_plantings_listing()')
plant_destination_id = get_random_record('ui.get_plant_destinations()')
sql_raw = 'SELECT * FROM ui.insert_plant(%s, %s, %s, %s, %s)'
params = [planting_id, plant_destination_id, '2017-05-01', 'This is a note', 'Text field']
qry_type = 'insert'
results = execute_query(sql_raw, params, qry_type)
# Used to update end-user ever `update_interval` records as it loops through...
i += 1
if (i - 1) % update_interval == 0:
elapsed = round(time.time() - start_time, 0)
print('Processed: %s records in %s seconds' % (i, elapsed))
# Pause for this many seconds
time.sleep(sleep_delay)
elapsed_time = time.time() - start_time
print('Completed! Took {} seconds.'.format(elapsed_time) )
Testing shouldn't take a lot of effort if you approach it correctly.
Security Considerations
Examples in this post demonstrate hosting a database using Amazon Web Services (AWS), a could computing provider. Hosting databases in the cloud should never be taken lightly, and you must ensure appropriate security controls are in place. RustProof Labs takes security very seriously and implements security in every layer possible. If you're unsure about the security of your databases and data, contact us.
Cybersecurity should be Priority #1 for your databases and data.
AWS Testing - Round 1
For the first test run I setup one AWS EC2 instance (t2.micro)
with PostgreSQL 9.5 installed and our TrackYourGarden
database loaded. I set it to run 1,000 iterations with no delay between loops. This effectively runs 2,000
SELECT queries and 1,000 INSERT queries. I ran 3 iterations of this test, each ran in 30-31 seconds,
working out to be 100 queries per second. At this rate, our database could handle nearly 9 million queries per day.
Except...
AWS CPU Credits and Limits
Since I started with just hammering the server with a ton of queries I quickly found out that when AWS talks about CPU credits and throttling, they aren't joking. These limits are well-documented and I reached them in a few minutes!
Had I let CPU credits accumulate for a while, it would have taken longer to reach the limits.
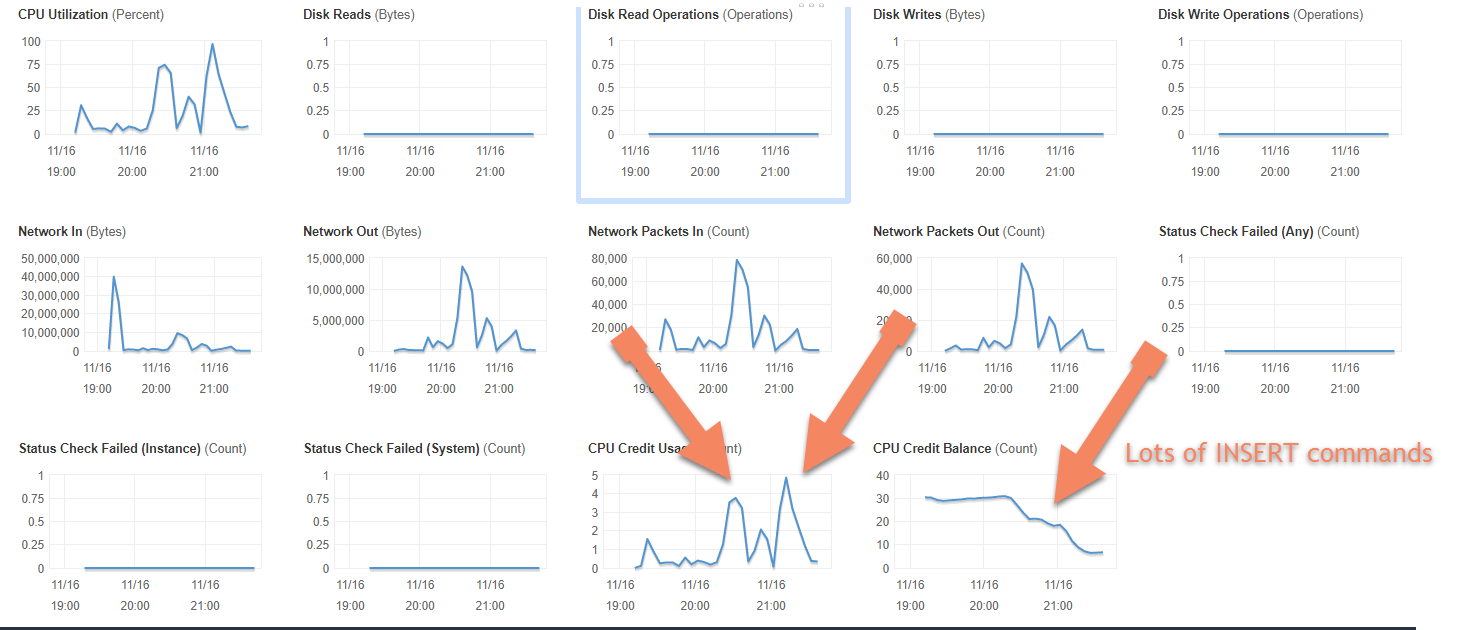
The screenshot below shows what happened on the EC2 instance when I ran the loop above without any delay. To start, I was getting a little more than 100 queries per second. The second big spike (just after 21:00) was when I ran 25,000 iterations of the above code. By the end of that run, CPU credits had pretty much ran out and the overall average was down to about 80 queries per second. Tests I tried running after that were terribly slow with less than 40 queries per second being executed.
Note: The slowdown is NOT related to PostreSQL. It's related to using a budget server with throttling for high-load testing.
Raspberry Pi Test
When I ran into the throttling issue mentioned above I realized I should be a bit more careful with my approach to testing. I also could have simply spooled up another EC2 instance but decided instead to run similar tests locally, using my Raspberry Pi 2 B. This Pi model has a quad-core 900 Mhz processor and 1 GB of RAM. While the processor and RAM speeds are lower than typical for modern hardware, its biggest limitation is that it is using a MicroSD card for its hard drive and those are notoriously slow for this type of work (lots of small, random read/writes).
I put the Raspberry Pi 3B to the test in PostgreSQL performance on Raspberry Pi!
While the AWS intance could handle bursts of 100 queries per second, the Pi topped out around 6 queries per second. While a tiny load compared to what the EC2 intance handled, that's still around 450,000 queries per day it could handle. I think it's pretty impressive that such affordable hardware can handle this level of load.
AWS Testing - Round 2
I wanted to do more testing in the AWS environment so spooled up pair of t2.nano servers w/ replication, one for the master the other setup as a read-only secondary. The only thing to note about the secondary server is that it's load was nearly zero throughout the entire test. In other words, it can keep up with a large number of writes with very little load, leaving plenty of headroom to offload read-queries to the secondary in the future.
This test run was modified to run a more realistic simulation of a lot of simultaneous users. To accomplish this I
used Python's multiprocessing module to set multiple threads (users) to run simultaneously.
In this example I'm running the sim_plant_insert function 30 times starting each
one 0.5 seconds after the previous run. Since each thread runs independently of the others, their timing in relation
to each other will vary as their queries take longer or slower to run. With 1,000 loops and each loop executing
three (3) queries, this will run 30 * 1000 * 3 = 90,000 queries.
My rough estimation is this load represents 400 - 600 highly active users, each one adding data as fast as possible.
import multiprocessing
jobs = []
for i in range(30):
p = multiprocessing.Process(target=sim_plant_insert)
jobs.append(p)
p.start()
time.sleep(0.5)
The total execution time was about 1,090 seconds, or roughly 5,000 queries per minute.
Observations
One AWS EC2 instance can handle very high load for burst activity but a more powerful server (vertical scaling) and connection pooling (horizontal scaling) should be used if that load is to be sustained. These tests showed the bottleneck is the single CPU and the associated credits.
To scale vertically, simply upgrade the AWS EC2 instance to a larger server with more CPU cores (and credits!) and RAM. To scale horizontally we simply need to add PGPool to provide connection pooling between the read-write master and the read-only secondary server(s).
During the last load, disk writes hovered between 250 - 500 KB/s. The disk reads are minimal because the same
SELECT queries were ran and either the OS or PostgreSQL cached the results
to keep those results handy.
PostgreSQL and Scalability
Every one of these tests has been conducted on budget hardware. These tests show that one budget PostgreSQL server can handle millions of queries per day. The t2.micro instance we used in our tests costs between $5-10 per month. Not bad at all. Even better is that by using streaming replication we could run four (4) servers to scale the load. With one as the master database server, two could be configured as secondary servers to handle read-only queries. The fourth server would run PgPool to provide load balancing for read-only queries and connection pooling to save resources.
This configuration could cost as low as $500 / year while providing load balancing, data redundancy, and geographic resilience to reduce risk of localized disasters. If heavy reporting queries need to run it's trivial to configure another replication server to dedicate to the task.
Parting Thoughts
The goal of this testing was to make sure a surge in usage wouldn't bring our planned database infrastructure to its knees. In a nutshell, it won't. Further, as load increases we have lots of room for scaling up to meet demand.
It was also fun to see that an older-model Raspberry Pi 2B+ running PostgreSQL, a full GUI, and a bunch of other
unnecessary software can handle a load of 250,000 queries per day (80,000 INSERT statements!).
A continuous load of that level
would likely wear the Pi out quickly, but I would argue that most databases in the wild run loads far below
this threshold.
PostgreSQL is a powerful relational database. These tests prove that when properly designed, it can handle significant load without breaking the budget.
 Mastodon
Mastodon