
Enhance your PostgreSQL Data Dictionary
This post continues the topic of creating a robust data dictionary in PostgreSQL.
My previous post on
building a data dictionary in PostgreSQL
focused on using built-in psql tools, such as \dn and \dt. It also quickly covered the use of comments
to document database objects.
Those tools and shortcuts are great and readily available, but beyond quick exploration tasks these built-in options don't provide enough functionality. This is especially true in today's data-filled world with
increasing regulation.
This post is part of the series PostgreSQL: From Idea to Database.
Meet pgdd: PostgreSQL data dictionary
The PostgreSQL Data Dictionary (pgdd) project,
available on GitHub, intends to improve our ability to document databases in PostgreSQL.
This open-source project super-powers your PostgreSQL databases by introducing additional
meta-tracking abilities.
It also makes the internal database meta-data more user accessible and user friendly through a
handy set of views. These views can be queried and joined using standard SQL syntax using any
tool you like.
pgddexists to make PostgreSQL data dictionaries more usable.
Data dictionary should be for everyone
Imagine an analyst with access to a PostgreSQL/PostGIS database. That database probably has
data from a variety of open and closed sources.
That analyst spends
quite a bit of time in QGIS, but very little time in psql. Being able to run
standard SQL type queries in their favorite tool makes the data dictionary more usable for this user.
If the analyst didn't know SQL, they could simply add the views from the database directly to QGIS as attribute tables. This would allow them to view the data dictionary directly in the GUI without even writing a single SQL query.
Example query
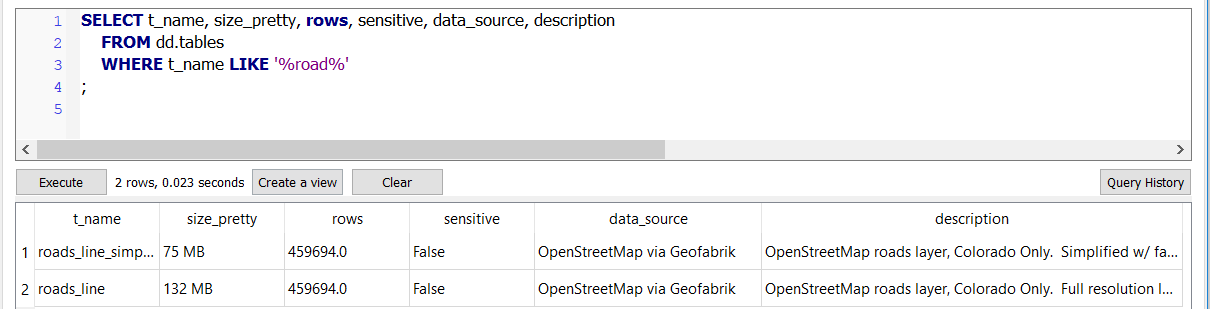
The query in the previous screenshot was an example query using the dd.tables meta-view. This query returns a list of tables in
the osm schema where the table name (t_name) includes road.
ryanlambert@osm=# SELECT t_name, size_pretty, data_source, description
FROM dd.tables
WHERE s_name = 'osm'
and t_name LIKE '%road%'
;
The data source and description columns provide helpful insight into what
data is contained in these two tables.
The results of this query show data size on disk, where the data comes from, and a more detailed explanation of what
each table contains. The use of pgdd makes it easy to see the size reduction of the simplified geometries,
down to 75 MB from 132 MB.
The table osm.roads_line_simplify10 is a reduced version of the osm.roads_line table, created
as discussed in my post PostGIS: Tame your spatial data.
Both tables contain
OpenStreet Map
data sourced via
Geofabrik.
┌───────────────────────┬─────────────┬─────────────────────────────┬───────────────────────────────────────────────────────────┐
│ t_name │ size_pretty │ data_source │ description │
╞═══════════════════════╪═════════════╪═════════════════════════════╪═══════════════════════════════════════════════════════════╡
│ roads_line_simplify10 │ 75 MB │ OpenStreetMap via Geofabrik │ OpenStreetMap roads layer, Colorado Only. Simplified w/ …│
│ │ │ │…factor of 10 from full resolution layer. │
│ roads_line │ 132 MB │ OpenStreetMap via Geofabrik │ OpenStreetMap roads layer, Colorado Only. Full resolutio…│
│ │ │ │…n layer. │
└───────────────────────┴─────────────┴─────────────────────────────┴───────────────────────────────────────────────────────────┘
(2 rows)
Installing
The
pgddproject is now a PostgreSQL extension! Visit the project page for updated install instructions. If you insist on installing the old version via Sqitch, check out commit 4cde448.
The recommended original way to install and manage pgdd is to
use Sqitch.
This installation is done per-database. If configuration management is used to deploy your database projects,
it is simple to wrap these installation instructions into Ansible roles, or other, to add this project to every
database as it is created.
pgdd creates the necessary database objects in a schema named dd in the target database.
Warning: If your database already has a schema named
ddyou should proceed with extreme caution.
Assumptions for these instructions:
- Using Linux or Mac
- PostgreSQL 9.5 +
- Your Git repositories are under
~/git - You have Sqitch installed
- Your
.pgpassfile is configured for thepg_user/pg_server/db_nameyou will use in the following command
Quick install
The following commands will clone the pgdd repository from GitHub and deploy it to the database you tell
sqitch to deploy to.
cd ~/git
git clone https://github.com/rustprooflabs/pgdd.git
cd ~/git/pgdd/db
sqitch deploy db:pg://< pg_username >@< pg_server >/< db_name >
Manual install
The pgdd project uses a simple numbering scheme for ordering the delta scripts, e.g 001, 002, etc.
If you want to deploy the database without using sqitch, you can script psql to deploy the scripts in
the proper order and it should work.
If you are considering this path, please reconsider learning Sqitch. It is far quicker to learn this simple tool than trying to roll your own deployment.
dd schema
This project does modify your database by creating a schema (dd) containing a few tables and views.
While this is an unfortunate requirement, I needed the ability to track more details about our databases
and I needed the easy ability to query this meta-data regardless of what tool I currently am logged into.
I chose the schema name of dd because it made logical sense I and couldn't think of too many good examples
of why an existing schema would already have that name.
dd tables
The tables created in the dd schema are used to store extra meta-data about various database objects.
The values populating the data_source column in the above query are stored in dd.meta_table.
That column and the sensitive flag are the main reasons for these meta_ tables to exist right now. I
expect them to be expanded over time as needed.
dd views
The views in the dd schema mostly rely on PostgreSQL's built-in system tables and join those to the extra dd.meta_ tables. These views make it very simple to explore your databases.
dd.schemasdd.tablesdd.columnsdd.functions
Add content
There are three main properties I try to set for each table:
descriptiondata_sourcesensitive
Revisiting the results from the earlier query:
┌───────────────────────┬─────────────┬─────────────────────────────┬───────────────────────────────────────────────────────────┐
│ t_name │ size_pretty │ data_source │ description │
╞═══════════════════════╪═════════════╪═════════════════════════════╪═══════════════════════════════════════════════════════════╡
│ roads_line_simplify10 │ 75 MB │ OpenStreetMap via Geofabrik │ OpenStreetMap roads layer, Colorado Only. Simplified w/ …│
│ │ │ │…factor of 10 from full resolution layer. │
│ roads_line │ 132 MB │ OpenStreetMap via Geofabrik │ OpenStreetMap roads layer, Colorado Only. Full resolutio…│
│ │ │ │…n layer. │
└───────────────────────┴─────────────┴─────────────────────────────┴───────────────────────────────────────────────────────────┘
Setting the description can be done even without pgdd installed, this column pulls from the values set using
PostgreSQL's built-in comment
functionality.
COMMENT ON TABLE osm.roads_line IS 'OpenStreetMap roads layer, Colorado Only. Full resolution layer.';
The other two properties (data_source and sensitive) are added in a row to the
table dd.meta_table.
INSERT INTO dd.meta_table (s_name, t_name, data_source, sensitive)
VALUES ('osm', 'roads_line', 'OpenStreetMap via Geofabrik', False);
Exploring columns
I use this type of query all the time. Here I want to see all the tables that have a column with a
specific column name. The following query shows an example of finding all the tables that have
an account_id column.
SELECT t.*
FROM dd.tables t
INNER JOIN dd.columns c ON t.s_name = c.s_name AND t.t_name = c.t_name
WHERE c.column_name = 'account_id';
It seems our trusty relational database (PostgreSQL, in this case) is pretty good at relating to itself!
I can easily switch this query to look for tables with BIT or JSONB columns.
Next steps for pgdd
I want to add functions to the dd schema to handle adding the comment and the appropriate meta_ record
a much simpler task. In with those functions I plan to handle scenarios such as marking a column as sensitive
ensures the table gets updated with the sensitive flag at the same time.
Summary
The pgdd project is very young, but it already handles a majority of the use cases I had for a built-in
data dictionary. As the project continues, I will try to update this post with updated examples.
Need help with your PostgreSQL servers or databases? Contact us to start the conversation!
 Mastodon
Mastodon