
Improved Quality in OpenStreetMap Road Network for pgRouting
Recent changes in the software bundled in PgOSM Flex resulted in unexpected improvements when using OpenStreetMap roads data for routing. The short story: routing with PgOSM Flex 1.2.0 is faster, easier, and produces higher quality data for routing! I came to this conclusion after completing a variety of testing with the old and new versions of PgOSM Flex. This post outlines my testing and findings.
The concern I had before this testing was that the variety of changes involved in preparing data for routing in PgOSM Flex 1.2.0 might have degraded routing quality. I am beyond thrilled with what I found instead. Quality of the generated network didn't suffer at all, it was a major win!
What Changed?
The changes started with PgOSM Flex 1.1.1 by bumping internal versions used in PgOSM Flex to Postgres 18, PostGIS 3.6, osm2pgsql 2.2.0, and Debian 13. There was not expected to be any significant changes bundled in that release. After v1.1.1 was released, it came to my attention that pgRouting 4.0 had been released and that update broke the routing instructions in PgOSM Flex's documentation. This was thankfully reported by Travis Hathaway who also helped verify the updates to the process.
pgRouting 4 removed the
pgr_nodeNetwork,pgr_createTopology, andpgr_analyzeGraphfunctions. Removing these functions was the catalyst for the changes made in PgOSM Flex 1.2.0. I had used thosepgr_*functions as part of my core process in data preparation for routing for as long as I have used pgRouting.
After adjusting the documentation
it became clear there were
performance issues using the replacement functions in pgRouting 4.0, namely in pgr_separateTouching().
The performance issue in the pgRouting function is reported as pgrouting#3010.
Working through the performance challenges resulted in
PgOSM Flex 1.1.2
and ultimately PgOSM Flex 1.2.0
that now uses a custom procedure to prepare the edge network far better suited
to OpenStreetMap data.
Ultimately, I knew for a long time that the networks generated using the legacy approach weren't perfect. However, they were "good enough" and instead of fixing the process building the network, I spent time to clean up the network. The "Fix Levels SQL" download available from my Route the Interesting Things talk is a good example of post-processing cleanup that should no longer be necessary.
Approach to Testing
I went into this testing assuming that differences in routing outcomes are
entirely, or at least predominately, influenced by the quality of the edge network
generated by the new osm.routing_prepare_roads_for_routing() procedure.
This assumption is based on the pgRouting 4.0 documentation which indicates
no significant changes to the
the pgr_dijkstra function.
The 4.0 changelog detail for this function reads "Combinations signature promoted to official."
With all software involved packaged within the PgOSM Flex Docker images, testing differences between versions was relatively easy. I used the two versions of the Docker image on two different ports. Versions used:
docker pull rustprooflabs/pgosm-flex:1.1.0
docker pull rustprooflabs/pgosm-flex:1.2.0
- PgOSM Flex 1.1.0 image uses Postgres 16.4, PostGIS 3.4, and pgRouting 3.6.2.
- PgOSM Flex 1.2.0 image uses Postgres 18.1, PostGIS 3.6, and pgRouting 4.0.0.
The Washington D.C. sub-region from Geofabrik was used for testing for it's compact size and quick processing. It also has the benefit of being largely urban where road networks are more likely to be fully connected.
See the PgOSM Flex documentation for more about running PgOSM Flex. If you are trying to test something and need assistance head to the project's Discussions page.
Data Preparation
The data preparation steps are version specific. The following sections outline the two processes.
Data Preparation: PgOSM Flex 1.1.0
The following three (3) queries were used in PgOSM Flex 1.1.0 with pgRouting 3.6.2 and represents the bulk of the time required to prepare data in the legacy version. The total time to run these functions for the Washington D.C. sub-region is 1 minute and 37 seconds (113 seconds).
SELECT pgr_nodeNetwork('routing.road_line', 0.1, 'id', 'geom');
SELECT pgr_createTopology('routing.road_line_noded', 0.1, 'geom');
SELECT pgr_analyzeGraph('routing.road_line_noded', 0.1, 'geom');
The full process for PgOSM Flex 1.1.0 is more than I want to include here. See the PgOSM Flex pgRouting 3 instructions to fully follow along. I'm only including the most-relevant parts here.
Running for a larger region, such as Colorado, takes more than 30 minutes.
Data Preparation: PgOSM Flex 1.2.0
The data prep step in PgOSM Flex 1.2.0 involves calling a single procedure,
osm.routing_prepare_roads_for_routing. This procedure
handles the entire process for creating the road network for routing.
This procedure processes the D.C. region in about 15 seconds. This is 87% faster
than the legacy process.
CALL osm.routing_prepare_roads_for_routing();
Colorado data processes in about 11 minutes (66% faster) with this procedure!
Name Changes between New and Legacy
The legacy table and column names were awkward. The new names in the PgOSM Flex 1.2.0 process are meant to be more understandable and clear aligning with overall project goals. The mapping in table names from legacy to new is:
routing.road_line_noded->osm.routing_road_edgerouting.road_line_noded_vertices_pgr->osm.routing_road_vertex
With the tables generated by PgOSM Flex it felt correct to bring them into the
osm schema with the core tables.
Generated Edge and Vertex Tables
The following two queries show the row counts generated in the edge and vertex tables. The results are combined in the table after the queries.
-- PgOSM FLex 1.1.0
SELECT e.edge_count
, v.vertex_count
FROM (SELECT COUNT(*) AS edge_count FROM routing.road_line_noded) e
, (SELECT COUNT(*) AS vertex_count FROM routing.road_line_noded_vertices_pgr )v
;
-- PgOSM FLex 1.2.0
SELECT e.edge_count
, v.vertex_count
FROM (SELECT COUNT(*) AS edge_count FROM osm.routing_road_edge) e
, (SELECT COUNT(*) AS vertex_count FROM osm.routing_road_vertex )v
;
┌─────────────┬────────────┬──────────────┐
│ PgOSM Flex │ edge_count │ vertex_count │
╞═════════════╪════════════╪══════════════╡
│ 1.1.0 │ 196879 │ 135749 │
│ 1.2.0 │ 194208 │ 132691 │
└─────────────┴────────────┴──────────────┘
The results from the PgOSM Flex 1.2.0 data preparation resulted in fewer edges (-1.3%) and vertices (-2.3%) compared to the PgOSM Flex 1.1.0 process. Seeing this decline in counts made me worry again about the quality of the generated edge network for routing.
This justified digging further, meaning it is time to compare output of generated routes! I decided to not try to isolate specific variances in the edge network and determine what was right/wrong, I was hoping to see impacts through real routing scenarios.
Route a few Routes
I start by picking four (4) random buildings from the D.C. OpenStreetMap
data to route between. I picked the first
two buildings to be spatially close to each other. The other
two buildings were picked by further random clicking.
I am starting my queries to use osm_id as a common starting
point between my two databases since each database's edge network is going to have
unique IDs that do not align to each other.
DROP TABLE IF EXISTS buildings_to_route;
CREATE TEMP TABLE buildings_to_route AS
SELECT *
FROM (VALUES (48039966)
, (48039313)
, (67260431)
, (67292550)
) AS v(osm_id)
;
With the osm_ids chosen, the next step is to find the closest vertex to each
building suitable for routing. The queries for this step are in the subsections
following the next screenshot. The screenshot shows two of the selected buildings
(blue polygons) along with the closest vertex to each (red point) for routing.
I visually validated the same points were chosen in both versions.
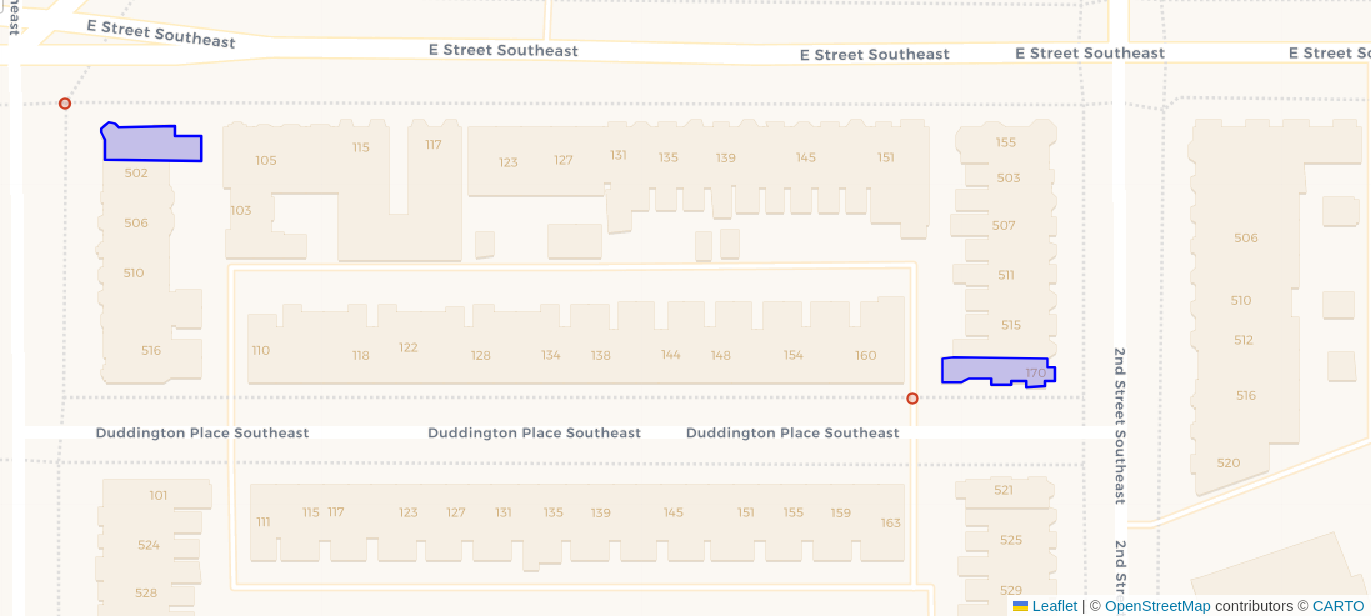
The queries to create the above image are in the following version-specific sections.
Both queries produce the same output other than the vertex_id values.
Query to identify vertices: v1.1.0
DROP TABLE IF EXISTS route_vertex;
CREATE TEMP TABLE route_vertex AS
WITH ranked AS (
SELECT b.osm_id, v.id AS vertex_id
, b.geom AS geom_building
, v.the_geom AS geom_vertex
, ROW_NUMBER()
OVER (
PARTITION BY b.osm_id
ORDER BY b.geom <-> v.the_geom
) AS rnk
FROM buildings_to_route br
INNER JOIN osm.building_polygon b
ON br.osm_id = b.osm_id
INNER JOIN routing.road_line_noded_vertices_pgr v
ON b.geom <-> v.the_geom < 50
) SELECT *
FROM ranked
WHERE rnk = 1
;
Query to identify vertices: v1.2.0
DROP TABLE IF EXISTS route_vertex;
CREATE TEMP TABLE route_vertex AS
WITH ranked AS (
SELECT b.osm_id, v.id AS vertex_id
, b.geom AS geom_building
, v.geom AS geom_vertex
, ROW_NUMBER()
OVER (
PARTITION BY b.osm_id
ORDER BY b.geom <-> v.geom
) AS rnk
FROM buildings_to_route br
INNER JOIN osm.building_polygon b
ON br.osm_id = b.osm_id
INNER JOIN osm.routing_road_vertex v
ON b.geom <-> v.geom < 50
) SELECT *
FROM ranked
WHERE rnk = 1
;
Create combinations of points to route
With our vertices identified for start and end points, we can create the combinations
to use for routing. The following query (works for both versions) generates N^2 - N rows
in the public.route_vertex_combos table. With 4 rows in the route_vertex table
it will generate 12 rows in the public.route_vertex_combos.
DROP TABLE IF EXISTS public.route_vertex_combos;
CREATE TABLE public.route_vertex_combos AS
SELECT a.osm_id AS osm_id_start, a.vertex_id AS vertex_id_start
, b.osm_id AS osm_id_end, b.vertex_id AS vertex_id_end
FROM route_vertex a
CROSS JOIN route_vertex b
-- Don't route to yourself :)
WHERE a.osm_id <> b.osm_id
;
The following table illustrates the 3 of the 12 records
that can use osm_id = 48039313 as the starting point. The vertex_id_start
and vertex_id_end columns will be used in the routing query.
┌──────────────┬─────────────────┬────────────┬───────────────┐
│ osm_id_start │ vertex_id_start │ osm_id_end │ vertex_id_end │
╞══════════════╪═════════════════╪════════════╪═══════════════╡
│ 48039313 │ 102626 │ 48039966 │ 102574 │
│ 48039313 │ 102626 │ 67260431 │ 101919 │
│ 48039313 │ 102626 │ 67292550 │ 3567 │
└──────────────┴─────────────────┴────────────┴───────────────┘
Length based Costs
Routing requires a cost to determine the best route. I am keeping the routing
scenario as simple as possible and am opting to use a simple length based cost.
The following queries creates the cost_length generated column to use with
simple, un-directed routing. The logic is the same between the two following queries,
only the names differ.
Costs: v1.1.0
ALTER TABLE routing.road_line_noded
ADD cost_length DOUBLE PRECISION NOT NULL
GENERATED ALWAYS AS (ST_Length(geom))
STORED;
COMMENT ON COLUMN routing.road_line_noded.cost_length IS 'Length based cost. Units are determined by SRID of geom data.';
Costs: v1.2.0
ALTER TABLE osm.routing_road_edge
ADD cost_length DOUBLE PRECISION NOT NULL
GENERATED ALWAYS AS (ST_Length(geom))
STORED
;
COMMENT ON COLUMN osm.routing_road_edge.cost_length IS 'Length based cost. Units are determined by SRID of geom data.';
Generate Routes
The following queries for routing with PgOSM Flex 1.1.0 and 1.2.0 are below. These queries are logically equivalent, only names have changed.
Both queries aggregate the routes to a single line per-route. The edge ids are stuffed into array columns in case they are useful in troubleshooting.
Query to Route: v1.1.0
DROP TABLE IF EXISTS public.my_routes;
CREATE TABLE public.my_routes AS
WITH route_raw AS (
SELECT c.osm_id_start, c.vertex_id_start, c.osm_id_end, c.vertex_id_end
, d.*
, n.the_geom AS node_geom, e.geom AS edge_geom
FROM public.route_vertex_combos c
CROSS JOIN pgr_dijkstra(
'SELECT e.id, e.source, e.target
, e.cost_length AS cost
, e.geom
FROM routing.road_line_noded e
',
c.vertex_id_start, c.vertex_id_end, directed := True
) d
LEFT JOIN routing.road_line_noded_vertices_pgr n ON d.node = n.id
LEFT JOIN routing.road_line_noded e ON d.edge = e.id
)
SELECT osm_id_start, vertex_id_start, osm_id_end, vertex_id_end
, COUNT(*) AS segments
, ARRAY_AGG(edge) AS edges
, SUM(cost) AS total_cost
, ST_Collect(edge_geom) AS geom
FROM route_raw
GROUP BY osm_id_start, vertex_id_start, osm_id_end, vertex_id_end
;
Query to Route: v1.2.0
DROP TABLE IF EXISTS my_routes;
CREATE TABLE my_routes AS
WITH route_raw AS (
SELECT c.osm_id_start, c.vertex_id_start, c.osm_id_end, c.vertex_id_end
, d.*
, n.id AS vertex_id
, n.geom AS node_geom, e.geom AS edge_geom
FROM public.route_vertex_combos c
CROSS JOIN pgr_dijkstra(
'SELECT e.edge_id AS id, e.source, e.target
, e.cost_length AS cost
, e.geom
FROM osm.routing_road_edge e
',
c.vertex_id_start, c.vertex_id_end, directed := False
) d
INNER JOIN osm.routing_road_vertex n ON d.node = n.id
LEFT JOIN osm.routing_road_edge e ON d.edge = e.edge_id
)
SELECT osm_id_start, vertex_id_start, osm_id_end, vertex_id_end
, COUNT(*) AS segments
, ARRAY_AGG(vertex_id) AS vertex_ids
, ARRAY_AGG(edge) AS edges
, SUM(cost) AS total_cost
, ST_Collect(edge_geom) AS geom
FROM route_raw
GROUP BY osm_id_start, vertex_id_start, osm_id_end, vertex_id_end
;
Compare Results
With the 4 chosen start/end points, we have 12 potential routes. How many routes did each version produce? This query aggregates the count of routes to and from each OpenStreetMap location. Version specific results are shown below.
WITH start_points AS (
SELECT c.osm_id_start
, COUNT(geom) AS routes_generated
FROM public.route_vertex_combos c
INNER JOIN public.my_routes r
ON c.osm_id_start = r.osm_id_start
AND c.osm_id_end = r.osm_id_end
GROUP BY c.osm_id_start
), end_points AS (
SELECT c.osm_id_end
, COUNT(geom) AS routes_generated
FROM public.route_vertex_combos c
INNER JOIN public.my_routes r
ON c.osm_id_start = r.osm_id_start
AND c.osm_id_end = r.osm_id_end
GROUP BY c.osm_id_end
)
SELECT sp.osm_id_start AS osm_id
, sp.routes_generated AS routes_as_start
, ep.routes_generated AS routes_as_end
FROM start_points sp
INNER JOIN end_points ep
ON sp.osm_id_start = ep.osm_id_end
;
Results from PgOSM Flex 1.1.0
The PgOSM Flex 1.1.0 routing method produced routes for 9 of the 12 combinations. The routes
with osm_id_start=67292550 did not generate routes.
Oddly, routes generated with that point as the end point, just not the start point.
This is one of the strange nuances I noticed repeatedly in the older routing network.
Routing in one direction simply won't work while the opposite direction routes.
This is happening without enforcing any one-way restrictions.
┌──────────┬─────────────────┬───────────────┐
│ osm_id │ routes_as_start │ routes_as_end │
╞══════════╪═════════════════╪═══════════════╡
│ 48039313 │ 3 │ 2 │
│ 48039966 │ 3 │ 2 │
│ 67260431 │ 3 │ 2 │
│ 67292550 │ 0 │ 3 │
└──────────┴─────────────────┴───────────────┘
Results from PgOSM Flex 1.2.0
The new routing method produced routes for all 12 combinations. Excellent!
┌──────────┬─────────────────┬───────────────┐
│ osm_id │ routes_as_start │ routes_as_end │
╞══════════╪═════════════════╪═══════════════╡
│ 48039313 │ 3 │ 3 │
│ 48039966 │ 3 │ 3 │
│ 67260431 │ 3 │ 3 │
│ 67292550 │ 3 │ 3 │
└──────────┴─────────────────┴───────────────┘
Explore Single Route Aggregates
The following query looks at the route details between OSM IDs 67292550 and 67260431
from the two versions of PgOSM Flex.
This shows PgOSM Flex 1.1.0 was unable to route from 67292550
to 67260431 even though it generated a route in the opposite direction.
Another interesting observation is the 1.1.0 route generated with a cost of 9200 while the 1.2.0 route had a route with cost 8914 (-3.1% shorter).
SELECT pgr_version(), osm_id_start, osm_id_end, segments, total_cost
FROM public.my_routes
WHERE osm_id_start IN (67260431, 67292550)
AND osm_id_end IN (67260431, 67292550)
ORDER BY osm_id_start, osm_id_end
;
┌─────────────┬──────────────┬────────────┬──────────┬───────────────────┐
│ PgOSM Flex │ osm_id_start │ osm_id_end │ segments │ total_cost │
╞═════════════╪══════════════╪════════════╪══════════╪═══════════════════╡
│ 1.1.0 │ 67260431 │ 67292550 │ 172 │ 9200.356624464805 │
│ 1.1.0 │ 67292550 │ 67260431 │ ¤ │ ¤ │
│ 1.2.0 │ 67260431 │ 67292550 │ 163 │ 8914.015802281903 │
│ 1.2.0 │ 67292550 │ 67260431 │ 163 │ 8914.01580228191 │
└─────────────┴──────────────┴────────────┴──────────┴───────────────────┘
Adjusting the filter in the query above to filter for a different pair of endpoints,
now using IN (67260431, 48039313).
The two routes generated for these endpoints in PgOSM Flex 1.1.0
have an 19% difference in cost (2059 vs 1673), depending on the direction traveled.
Again, since these queries are not currently enforcing one-way rules,
this is unexpected to get routes and costs from pgr_dijkstra.
In PgOSM Flex 1.2.0, both directions use the same route with the same costs.
Further, this version of the route is 21% shorter than the shorter of the 1.1.0 results,
with total_cost=1328.
┌─────────────┬──────────────┬────────────┬──────────┬───────────────────┐
│ PgOSM Flex │ osm_id_start │ osm_id_end │ segments │ total_cost │
╞═════════════╪══════════════╪════════════╪══════════╪═══════════════════╡
│ 1.1.0 │ 48039313 │ 67260431 │ 61 │ 2059.039939284777 │
│ 1.1.0 │ 67260431 │ 48039313 │ 64 │ 1673.206485686198 │
│ 1.2.0 │ 48039313 │ 67260431 │ 45 │ 1328.042968118372 │
│ 1.2.0 │ 67260431 │ 48039313 │ 45 │ 1328.042968118372 │
└─────────────┴──────────────┴────────────┴──────────┴───────────────────┘
Checking More Routes
The initial tests from the 4 chosen buildings showed signs that the newer data preparation process was an improvement! The new road edge network produced routes for 100% of the test routes while the older edge network produced only 75% of the routes. Will this pattern hold with wider testing?
The following query replaces the manual list of osm_id values with a query to
pull 25 random buildings, easily adjusted for a different LIMIT N.
Remember, the following step produces N^2 - N routes to generate so using
N = 25 results in 600 potential routes.
-- Get N random buildings that have a road_vertex within 50 meters
-- This N grows exponentially in later step via the cartesian join to route
-- between all N chosen points.
DROP TABLE IF EXISTS buildings_to_route;
CREATE TEMP TABLE buildings_to_route AS
SELECT DISTINCT b.osm_id, random() as r
FROM osm.building_polygon b
ORDER BY random()
LIMIT 25
;
The remainder of the testing for this uses the queries already outlined above, just with the N=25 for input buildings. This should generate 600 routes, in the case of all possible routes being generated.
Note: The random list of buildings was only used if 25 buildings selected all matched to a routable vertex. The proximity search was increased to 100 meters (from 50 represented in above queries) to increase match rate.
After creating the public.my_routes table, I ran the following queries to provide statistics
about generated routes. The first query counts how many routes (of the expected 600)
were generated. Knowing this type of testing involves randomness, three (3) consecutive
runs were documented and results presented. While only 3 sets of output are presented
here, many more tests were ran throughout the course of writing this post.
The gist of my findings presented here were consistent through all of my testing.
SELECT pgr_version(), COUNT(*)
FROM public.my_routes
;
The next query generates statistics about routing based on the input vertices. The same queries work for both versions. Results are discussed in the following sub-sections.
WITH start_points AS (
SELECT c.osm_id_start
, COUNT(geom) AS routes_generated
FROM route_vertex_combos c
INNER JOIN public.my_routes r
ON c.osm_id_start = r.osm_id_start
AND c.osm_id_end = r.osm_id_end
GROUP BY c.osm_id_start
), end_points AS (
SELECT c.osm_id_end
, COUNT(geom) AS routes_generated
FROM route_vertex_combos c
INNER JOIN public.my_routes r
ON c.osm_id_start = r.osm_id_start
AND c.osm_id_end = r.osm_id_end
GROUP BY c.osm_id_end
), aggs AS (
SELECT sp.osm_id_start AS osm_id
, sp.routes_generated AS routes_as_start
, ep.routes_generated AS routes_as_end
FROM start_points sp
INNER JOIN end_points ep
ON sp.osm_id_start = ep.osm_id_end
)
SELECT v.vertex_count
, COUNT(DISTINCT osm_id) AS vertex_routed
, v.vertex_count - COUNT(DISTINCT osm_id) AS vertex_missing_routes
, v.vertex_count - 1 AS max_possible_routes_per_vertex
-- I expect to be able to compute round trips, next two columns
-- should be the same if that happens
, AVG(routes_as_start) AS routes_as_start_avg
, AVG(routes_as_end) AS routes_as_end_avg
FROM aggs
CROSS JOIN (
SELECT COUNT(DISTINCT osm_id_start) AS vertex_count FROM route_vertex_combos
) v
GROUP BY v.vertex_count
;
Routes with PgOSM Flex 1.1.0
The edge network from PgOSM Flex 1.1.0 results in 61 - 74% of routes being generated in this testing. The counts here are out of 600 potential routes.
- 74% (443 routes generated)
- 61% (364 routes generated)
- 70% (420 routes generated)
These results are inline with the initial results showing 9/12 routes generated, and were represented in the various test runs that weren't the 3 shown here.
The results from the second query shows the variation in quality of generated routes.
When the routes_as_start_avg differs from routes_as_end_avg that indicates
routes can be generated in one direction but not both.
The use of an average on this metric was used to make this table simpler, what
you'd see on the non-aggregated values is every row has the same values for those
columns. If there had been variation in values I would have used min/max or some other
way to present the information.
In the case of the middle row in the following table, 19 of the points could be used as a start point and 18 used as an end point. Looking at the 3rd row indicates 22 points could be a start point while only 18 were usable as end points. Why? 🤷
┌──────────────┬───────────────┬───────────────────────┬────────────────────────────────┬─────────────────────┬─────────────────────┐
│ vertex_count │ vertex_routed │ vertex_missing_routes │ max_possible_routes_per_vertex │ routes_as_start_avg │ routes_as_end_avg │
╞══════════════╪═══════════════╪═══════════════════════╪════════════════════════════════╪═════════════════════╪═════════════════════╡
│ 25 │ 19 │ 6 │ 24 │ 20.0000000000000000 │ 21.0000000000000000 │
│ 25 │ 16 │ 9 │ 24 │ 19.0000000000000000 │ 18.0000000000000000 │
│ 25 │ 17 │ 8 │ 24 │ 22.0000000000000000 │ 18.0000000000000000 │
└──────────────┴───────────────┴───────────────────────┴────────────────────────────────┴─────────────────────┴─────────────────────┘
Routes with PgOSM Flex 1.2.0
In every example with 25 vertices to use, all 600 routes were generated when using PgOSM Flex 1.2.0. This means the second post-routing validation query returned the same values every time, only represented by one row here. Each of the 25 vertices generated 24 routes in both directions. I did not fully validate every generated route, but in the routes I checked they appear valid given the flexible routing scheme used (no access controls, no one-way controls, but otherwise valid networks).
┌──────────────┬───────────────┬───────────────────────┬────────────────────────────────┬─────────────────────┬─────────────────────┐
│ vertex_count │ vertex_routed │ vertex_missing_routes │ max_possible_routes_per_vertex │ routes_as_start_avg │ routes_as_end_avg │
╞══════════════╪═══════════════╪═══════════════════════╪════════════════════════════════╪═════════════════════╪═════════════════════╡
│ 25 │ 25 │ 0 │ 24 │ 24.0000000000000000 │ 24.0000000000000000 │
└──────────────┴───────────────┴───────────────────────┴────────────────────────────────┴─────────────────────┴─────────────────────┘
Summary
My findings from this testing gives me confidence that the network preparation in PgOSM Flex for OpenStreetMap roads is an improvement over prior instructions and resulting route quality. I do not plan to invest further efforts to exploring the differences with the older versions. I am confident enough that the newer data is the better source, and will focus efforts on ensuring that process provides the most accurate routing possible.
With these findings in place, I can proceed with exploring the routing data quality for real-world uses.
Need help with your PostgreSQL servers or databases? Contact us to start the conversation!
 Mastodon
Mastodon