
Hosting a set of Postgres Demo databases
In April 2023, I submitted my proposal for a full-day pre-conference at PASS 2023. My chosen topic was focused on PostGIS, titled GIS Data, Queries, and Performance. A key part of my submission was that the session would be an interactive, follow-along type design. Julie and I believe that doing is key to learning so we wanted to enforce that as much as possible. The plan was to use real data and queries to teach a nuanced, technical topic to an audience of unknown size or background. I also knew that PASS is very much a Microsoft focused community.
Knowing these things, I could not assume specific pre-existing knowledge about Postgres and PostGIS. I also didn't want to assume they had a Postgres 15 instance with PostGIS immediately available. I decided the best approach was to provide participants each a demo Postgres database so they didn't have to worry about those steps. These demo databases would be pre-loaded with the same data and extensions I used for my demos. This would allow participants to run the same queries, on the same data, on the same general hardware.
Of course, when my proposal was accepted then I realized I had to figure out how I was actually going to deliver! This post explains how I deployed demo databases to the participants of my PASS 2023 pre-con session.
The net result was a reliable, secure (enough), scalable, and affordable setup.
Goals
Before explaining how I approached this challenge, let's look at some of my goals for this effort. My primary goal was to provide every user with the same access to a positive learning experience. A full day pre-conference is an investment, and I wanted to make sure I did everything I could to provide positive returns on your investment.
For this, I needed to:
- Provide instances for
Nusers, without costing a fortune - Pre-load custom database (1 GB data)
- Give participants
<the right permissions> - Avoid one person hammering their demo DB from affecting other instances
- Provide predictable timings / query plans
- Make it easy to support / troubleshoot
- Include a variety of extensions
The detail that was most limiting to my options was the range
of extensions I planned to use throughout the day.
PostGIS itself wasn't a problem. PostGIS is supported by all major managed
Postgres services that I know of. The other extensions I use are not as popular
as PostGIS, and that's where things start getting tricky. Other extensions used were
h3-pg,
PgDD, and convert.
The h3-pg extension appears to be gaining traction, yet it's not near the level
of adoption of PostGIS and I don't think it is supported on any managed Postgres
services yet.
The PgDD and convert extensions are custom extensions I built and maintain using the
pgrx framework.
Using these extensions limits my options to hosting my own Postgres.
Even if I wasn't limited by extension availability, it is highly unlikely I would have used managed Postgres instances. My experience with those services is you get to pay 50% more for 20% less performance. Max Kremer recently published similar findings.
Approach
In the end, I settled on deploying groups of Postgres instances by running Docker containers. The Docker image for the demo was a slightly modified version of our PgOSM Flex image. PgOSM Flex already did the heavy lifting of providing a container with PostGIS, OpenStreetMap data, and the PgDD extension. I added the convert extension to PgOSM Flex, which is now part of the core image for that project. The other change I made for the demo was to include the h3-pg extension. I ultimately rejected that change from the base PgOSM Flex image because it significantly increased build time and image size in unacceptable ways.
The Docker containers were hosted on Digital Ocean instances, configured via Ansible.
I tested various sizes of hosts and container density and found that my general approach
scaled reliably up to 20 containers w/ 16 vCPU and 32 GB RAM.
I limited the Docker container resources
using --cpus=1.2 --memory=1024m to slightly over-commit the CPU but under-commit RAM.
My thoughts on this portion are that contention on the CPU could slow things down, but contention
on RAM can crash things.
The demo database was created using PgOSM Flex following steps similar to what is outlined in my post Load the Right Amount of OpenStreetMap Data.
Testing
In the weeks leading up to the conference I spent a decent amount of time testing my setup.
A lot of this testing involved setting up multiple containers, hammering some of them
with pgbench while pretending I was a real user on my own container. I practiced
my demo queries with this going on and compared timings, plans, and overall experience.
I was pleasantly surprised by how stable the performance remained through my testing.
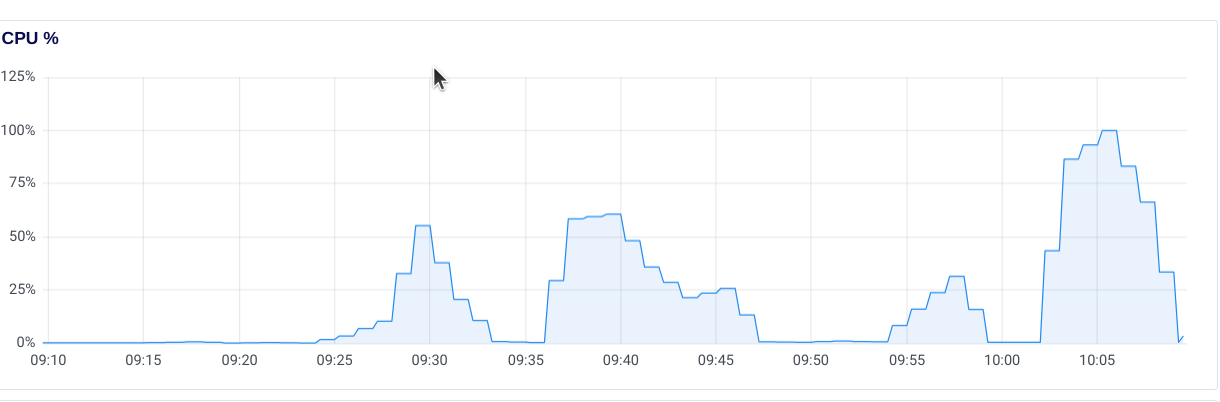
The following code block shows one example of running pgbench using custom test
queries in my pgbench-tests
project. The screenshot following the code block shows CPU load over 30 minutes
from testing a few different scenarios.
pgbench -c 2 -j 1 -T 300 -P 60 \
-U pgosm_flex -h localhost -p 5480 \
-s 10 \
-f tests/openstreetmap/osm-seattle-pass2023--trees-benches.sql@5 \
-f tests/openstreetmap/osm-seattle-pass2023--tree-bench-county-aggs.sql \
-f tests/openstreetmap/osm-seattle-pass2023--major-roads-in-place.sql@3 \
-f tests/openstreetmap/osm-seattle-pass2023--roads-in-place.sql@3 \
pass2023 &> pgbench_1.log
The output from
pgbenchwasn't my main goal of using that tool for this testing, thus is not shared in this post.
The other testing I did prior to the day of the event was related to what do if/when things went wrong. I practiced scaling up, scaling down, deploying new instances in a hurry, and so on. My use of Ansible plus some additional scripting made this a fairly easy step.
Secure (enough)
I don't want to share this setup without a note on security. One common piece of wisdom shared by DBAs:
"Don't expose your database to the internet." -- DBAs everywhere
This isn't wisdom scoped to Postgres DBAs... MS SQL Server, Maria DB, and Oracle DBAs will agree: your database belongs behind a firewall at minimum.
To provide these databases to participants with the lowest amount of friction, I did violate this rule. That's why I say "secure (enough)" -- I violated this common best practice. I did so knowing that nothing important or private data-wise was involved with those instances, and that I could quickly remedy the situation if needed. While I used a somewhat-predictable pattern in the passwords assigned per instance, it didn't seem likely that any brute force guessing would happen in the short time the instances were online.
A few months ago I setup a honeypot instance running Postgres on port 5433 with a poor password. It took less than 7 days for it to become compromised, detected by a fully pegged CPU from an apparent cryptominer.
In Hindsight
I am really happy about how this setup worked. I reached my technical goals and my participants were happy with the demo database setup. There were two (2) technical issues during the session, with only one being related to the demo database!
- Slow email sending credentials in the morning
- Short hiccup in the afternoon with an unexpected performance cliff
With only one short-lived hiccup related to the demo databases, I didn't even try to investigate. For all I know it could have been a WiFi issue!
One of my key non-technical goals was being affordable. This approach cost a total of $9.16 per participant. That total cost includes my testing in the weeks leading up to the session.
Deploying Docker Containers
My post with pre-con materials briefly explains the logic in the following script. The version on that prior page explains how to run one container and load the data. This script is closer to what I used to setup all of the containers.
source ~/.pgosm-pass2023-a001
# Set starting port number
PG_DOCKER_PORT=5480
CONTAINER_COUNT=12
PASSWORD_BASE=BeginningOfPassword
PASSWORD_COUNTER=10
PWS_CREATED_LOG='docker-pws.log'
echo 'Password tracking for created database containers...' > $PWS_CREATED_LOG
echo 'Port Password' >> $PWS_CREATED_LOG
for (( DOCKER_NAME_NUMBER=0; DOCKER_NAME_NUMBER<$CONTAINER_COUNT; ++DOCKER_NAME_NUMBER)); do
DOCKER_NAME=pgosm$DOCKER_NAME_NUMBER
echo "Starting Docker container ${DOCKER_NAME} on port ${PG_DOCKER_PORT}..."
docker run --name $DOCKER_NAME -d \
--cpus=1.2 --memory=1024m \
--restart=unless-stopped \
-v ~/pgosm-data:/app/output \
-v /etc/localtime:/etc/localtime:ro \
-e POSTGRES_PASSWORD=$POSTGRES_PASSWORD \
-p $PG_DOCKER_PORT:5432 -d rustprooflabs/pgosm-flex:h3 \
-c jit=off \
-c max_parallel_workers_per_gather=2 \
-c work_mem=10MB \
-c shared_preload_libraries='pg_stat_statements' \
-c track_io_timing=on \
-c shared_buffers=250MB \
-c max_wal_senders=0 -c wal_level=minimal \
-c max_wal_size=10GB \
-c checkpoint_timeout=300min \
-c checkpoint_completion_target=0.9 \
-c random_page_cost=1.1
echo "pausing..."
sleep 10
# Prepare the database and load the data file.
psql -U postgres -d postgres -h localhost -p $PG_DOCKER_PORT -c "CREATE DATABASE pass2023;"
USER_PW=$PASSWORD_BASE$PASSWORD_COUNTER
echo "${PG_DOCKER_PORT} ${USER_PW}" >> $PWS_CREATED_LOG
psql -U postgres -d pass2023 -h localhost -p $PG_DOCKER_PORT -c "CREATE ROLE pgosm_flex WITH LOGIN PASSWORD '$USER_PW';"
psql -U postgres -d pass2023 -h localhost -p $PG_DOCKER_PORT -c "GRANT CREATE ON DATABASE pass2023 TO pgosm_flex;"
psql -U postgres -d pass2023 -h localhost -p $PG_DOCKER_PORT -c "GRANT CREATE ON SCHEMA public TO pgosm_flex;"
psql -U postgres -d pass2023 -h localhost -p $PG_DOCKER_PORT -c "CREATE ROLE dd_read WITH NOLOGIN;"
psql -U postgres -d pass2023 -h localhost -p $PG_DOCKER_PORT -c "CREATE ROLE convert_read WITH NOLOGIN;"
psql -U postgres -d pass2023 -h localhost -p $PG_DOCKER_PORT -c "CREATE EXTENSION IF NOT EXISTS pg_stat_statements;"
psql -U postgres -d pass2023 -h localhost -p $PG_DOCKER_PORT -c "GRANT EXECUTE ON FUNCTION pg_stat_statements_reset TO pgosm_flex;"
# 30 - 45 seconds
psql -U postgres -d pass2023 -h localhost -p $PG_DOCKER_PORT -f postgis-precon-pass-washington-osm.sql
psql -U postgres -d pass2023 -h localhost -p $PG_DOCKER_PORT -f extension-pgosm-flex-perms.sql
# Increment port number for next
let PG_DOCKER_PORT++
# Incrementing by 2 to be "clever" (eyeroll)
let PASSWORD_COUNTER++
let PASSWORD_COUNTER++
echo "Pausing before moving on to next container..."
sleep 10
done
Summary
This post explains how I provided demo Postgres instances for participants in our full-day GIS Data, Queries and Performance pre-conference session. These instances provided a unified experience for all participants, giving them direct access to the data, extensions, and even predictable query plans and timings! Live demos are hard to do, and harder to share. I feel that this approach worked well enough for this first round to consider as a framework for future live demos.
Need help with your PostgreSQL servers or databases? Contact us to start the conversation!
 Mastodon
Mastodon