
Psycopg3 Initial Review
If you use Postgres and Python together you are almost certainly familiar with psycopg2. Daniele Varrazzo has been the maintainer of the psycopg project for many years. In 2020 Daniele started working full-time on creating psycopg3, the successor to psycopg2. Recently, the Beta 1 release of psycopg3 was made available via PyPI install. This post highlights two pieces of happy news with psycopg3:
- Migration is easy
- The connection pool rocks
As the first section shows, migration from psycopg2 to psycopg3 is quite easy. The majority of this post is dedicated to examining pyscopg3's connection pool and the difference this feature can make to your application's performance.
Migration
Easy migration is an important feature to encourage developers to upgrade. It is frustrating when a "simple upgrade" turns into a cascade of error after error throughout your application. Luckily for us, psycopg3 got this part right! In the past week I fully migrated two projects to psycopg3 and started migrating two more projects. So far the friction has been very low and confined to edge case uses.
The following example shows a simplified example of how my projects have
used psycopg2.
import psycopg2
import psycopg2.extras
conn = psycopg2.connect(db_string)
cur = conn.cursor(cursor_factory=psycopg2.extras.DictCursor)
cur.execute(sql, params)
The next example shows how psycopg3 is imported, simply referenced as psycopg.
When establishing the cursor (cur), cursor_factory
has changed to row_factory and has a new approach to returning data
as a dict.
Outside of these basic name changes, no other application code required changing.
import psycopg
conn = psycopg.connect(db_string)
cur = conn.cursor(row_factory=psycopg.rows.dict_row)
cur.execute(sql, params)
The psycopg3 documentation on row factories explains this implementation in more detail. It also covers advanced options such as
class_row. Theclass_rowimplementation looks nifty though I haven't had time to try it out.
Connection pooling
The connection pool
in psycopg3 is a feature that caught my attention a few
months ago. This post covers some of the shortcomings in psycopg2's implementation addressed by psycopg3.
With the new psycopg_pool package (remember, no "3"!) it is easy to
establish an efficient in-app connection pool. From the application side this has the important
characteristic of removing the overhead related to establishing connections
from queries. Many modern webapps run multiple queries for every
page load and can be a source of significant portion of the total overhead
of database interactions.
The remainder of this post illustrates how this impacts performance,
and ultimately the end user experience.
I am not directly looking at the impact on Postgres in this post. Here are one two three four sources on the topic.
The psycopg3 connection pool is implemented in a dedicated psycopg_pool
package, install via pip.
pip install psycopg_pool
Setup
For this round of testing I am using my laptop with 6-cores/12-threads and 64 GB RAM to run the webapp and simulated load. The application is connected to Postgres 12 on a Raspberry Pi 4 with Postgres data on an external USB3 SSD drive. The connection between webapp an database is via local WiFi. The user load is simulated using Locust.
The app being tested is an internal reporting application built using Flask. The application displays tabular, aggregated and/or trend data to end users. Five (5) common routes (reports pages) were chosen to test with two fast reports and three (3) that are slower to build. Each of the routes sends between 4 and 10 queries to Postgres. Without a connection pool, each query opens and closes its own connection, meaning a single page load will open and close a few Postgres connections.
Test shape
Locust makes it easy to define a test's "shape", or pattern of users. The following chart from Locust's output shows the number of users simulated by Locust throughout the duration of the tests. It starts with a small number of users and ramps up to 25, then 50, then 70 users before ramping back down. Each "user" performs a "task" and then waits between 1 - 4 seconds before performing another task.
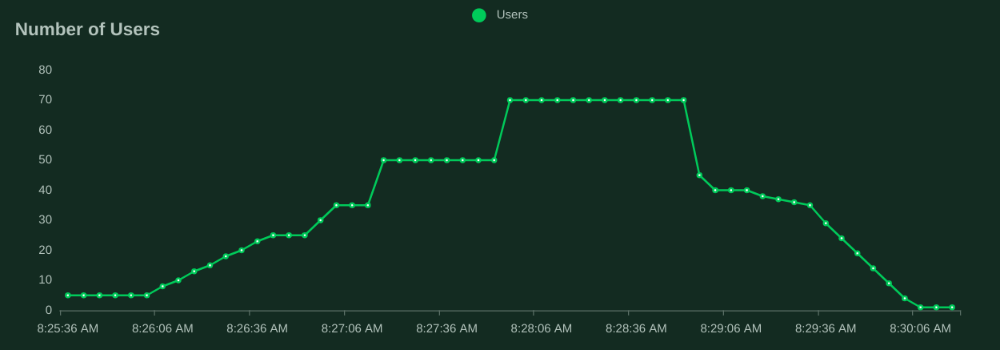
The total duration for these tests is under five (5) minutes. More robust testing will hopefully be done in the future, I expect those results will confirm the overall theme identified here.
Requests per second
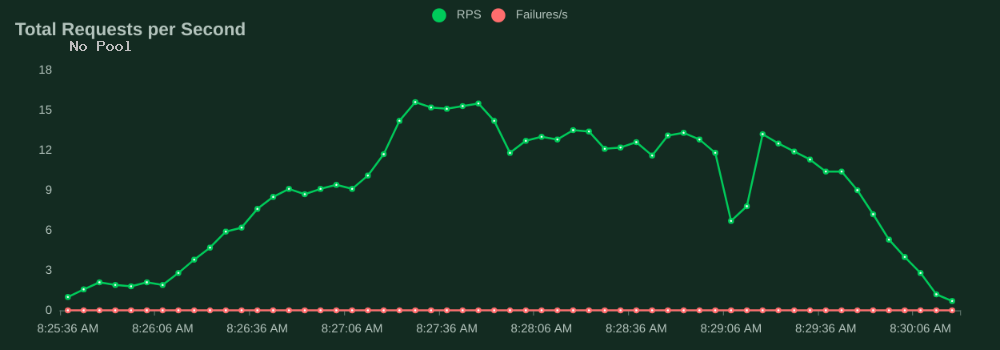
One chart Locust provides is the trend of Requests per Second (RPS). A "request" here a page view via the webapp and translates to multiple Postgres queries. Without the connection pool, at 50 users it was able to maintain about 15 RPS. As the number of users ramps up from 50 to 70 users, the RPS actually decreased from 15 RPS to 12 RPS.
Now with the connection pool, the test stage with 50 users is able to serve 20 RPS, 33% more than the no-pool test. As users scale from 50 to 70, the connection pool test increases to 30 RPS (vs 12).
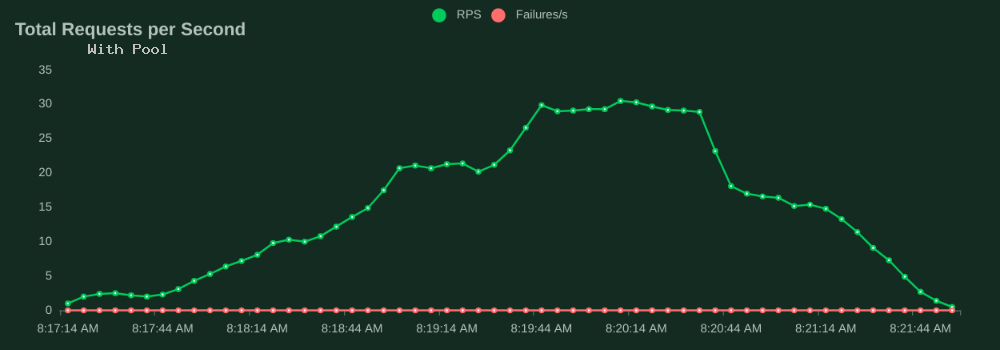
I did not push the user load beyond 70 users for this post. At the 70-user mark with the in-app connection pool, the Pi still had a decent amount of idle CPU capacity.
Response times
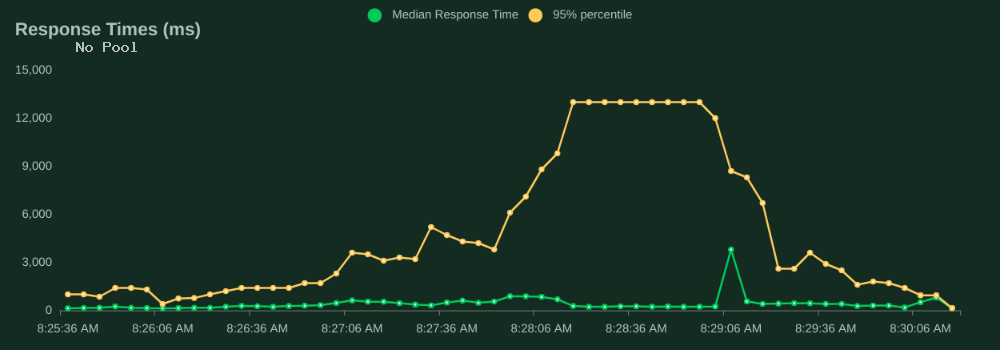
Locust also tracks response time as a trend showing the median and 95% percentile times. The response time reported represents how long the end user's browser would be waiting for data to be returned. Without a connection pool, the 95th percentile response time rises to 3 seconds (3,000 ms) by the time that there are 10 simulated users. By the time there are 70 users the response time has completely tanked.
Using psycopg3's connection pool the 95th percentile stays well below 1 second throughout the entire test. The median response time remains comfortably under 100 ms.

Results by page
The previous sections show trend charts of the data throughout the duration
of the tests. This section shows the aggregated results by the different
routes that were being served.
The /page1 and /page2 routes are the lightweight routes that
generally return much faster than the other three routes tested.
The /page3, /page4, and /page5 routes are the more complicated
and expensive reports. These three routes are also on the higher end of query
count per route.
The distribution of requests by page is defined in the Locust test via task
weights. The weights for this test were informed by real-world traffic where /page1 had a weight of 5, /page2 a weight of 3, and the others
a weight of 1.
Using the connection pool was able to serve 4,277 requests, 66% more
requests than when the pool was not used.
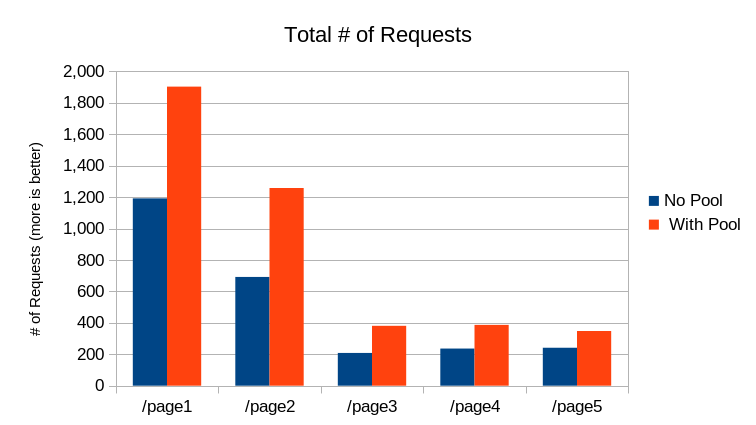
The Median Response time by Page chart shows the faster /page1 and
/page2 routes managed to keep median response times under 300 ms. Though
comparing to the same routes with the connection pool (29 ms)
shows the connection pool was noticeably faster.
The remaining 3 slower routes saw the same type of difference in median
response time.
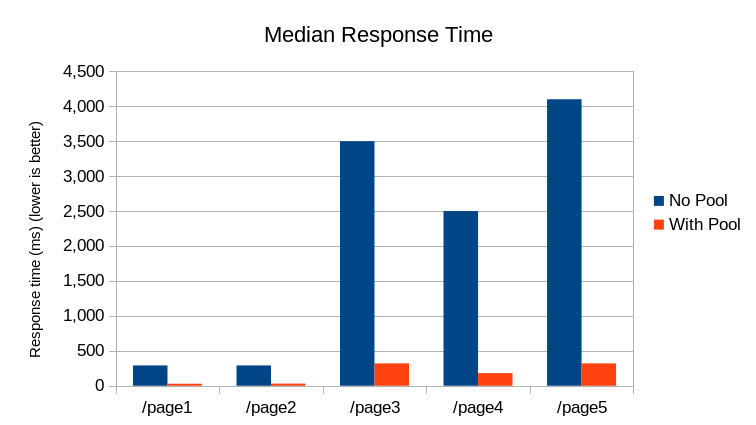
By using psycopg3's connection pool the application can (a) handle more total requests (b) with faster response times and (c) with more predictable performance.
Wrapping up
The tests in this post showed using pyscopg3's connection pool can benefit application performance in two ways:
- Improved performance at all scales
- Improved scalability
This testing is inline with the results I put in this Twitter thread back in March 2021. The thread includes results using the psycopg3-connpool demo project I started to experiment with. That round of testing found similar results to the testing in this post, showing the pyscopg3 connection pool provided 85% faster results than using direct connections. The thread includes more insight into the impact on Postgres via pgBench results and htop.
Gave the #psycopg3 connection pool to #PostgreSQL an initial test run...
— RustProof Labs 🐘 (@RustProofLabs) March 29, 2021
Spoiler: Loving it! Thank you @psycopg!!
A thread. 1/?https://t.co/p49q3QfgFB
Summary
Even though psycopg3 is still in the beta phase I eagerly converting our applications from psycopg2. The easy migration combined with the in-app connection pool is giving me an easy win in multiple Python projects. Of course, I've only touched on two details of psycopg3 so here are a few more reading options.
- Why psycopg3 was necessary
- Some notes on changes
- Changes to
copy
Having used psycopg2 for the past decade it is exciting to see a well designed upgrade available that I'll likely use for the coming decade. If psycopg2 and/or psycopg3 is important to you consider adding your name as a sponsor. Daniele has done, and continues to do, amazing work that benefits countless people and organizations. Thank you!
Need help with your PostgreSQL servers or databases? Contact us to start the conversation!
 Mastodon
Mastodon