
Large Text in PostgreSQL: Performance and Storage
Storing large amounts of data in a single cell in the database has long been a point of discussion. This topic has surfaced in the form of design questions in database projects I have been involved with over the years. Often, it surfaces as a request to store images, PDFs, or other "non-relational" data directly in the database. I was an advocate for storing files on the file system for many, if not all, of those scenarios.
Then, after years of working with PostGIS data
I had the realization that much of my vector data that performs
so well when properly structured and queried, was larger and more complex
than many other blobs of data I had previously resisted.
Two years ago I made the decision to store images in a production database
using BYTEA. We can guarantee there are a limited number of images
with a controlled maximum resolution (limiting size) and a specific use
case. There was also the knowledge that caching the images in the frontend
would be an easy solution if performance started declining.
This system is approaching two years in production with great performance.
I am so glad the project has a singular data source: PostgreSQL!
This post is part of the series PostgreSQL: From Idea to Database.
Testing TEXT
In this post I test PostgreSQL 12's TEXT data type with a variety of
data sizes, focused on performance with larger blocks of text.
The TEXT format provides the ability to store any length
of text within the field. The documentation explains the storage
characteristics:
"Long strings are compressed by the system automatically, so the physical requirement on disk might be less. Very long values are also stored in background tables so that they do not interfere with rapid access to shorter column values. In any case, the longest possible character string that can be stored is about 1 GB." -- Postgres docs
You can find more details about when the compression kicks in on the
TOAST page.
In a nutshell, when a value is wider than 2 kB
(set by TOAST_TUPLE_THRESHOLD)
and the default EXTENDED storage method is used, compression
automatically kicks in. This information led me to ask the following questions:
- How much compression is achieved on
TEXT? - How does compression affect performance?
Compression Threshold
To get started I wanted to get a feel for where compression kicked in and
the rough performance characteristics around that threshold.
I created a Jupyter notebook (Download the Jupyter notebook)
with code to create a series of tables with differing base_length
and variance values, collecting details along the way.
The script creates a number of identical tables named using
the following format.
CREATE TABLE dev_text.b%(base_length)s_v%(variance)s
(
id BIGINT NOT NULL GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY,
val TEXT NOT NULL
);
An example table name would be dev_text.b65_v25.
The INSERT command is where the difference happens by loading data
with varying sizes of text.
With base_length=0 the strings inserted have a length in the range
of 32 - 800 characters. With base_length=65, the range of string
lengths is 2112 - 2880. The variance parameter was consistently
set to 25 for all examples in this post.
INSERT INTO dev_text.b65_v25 (val)
SELECT repeat(md5(random()::TEXT),
65 + ceil(random() * 25)::INT)
FROM generate_series(1, 1000000) x;
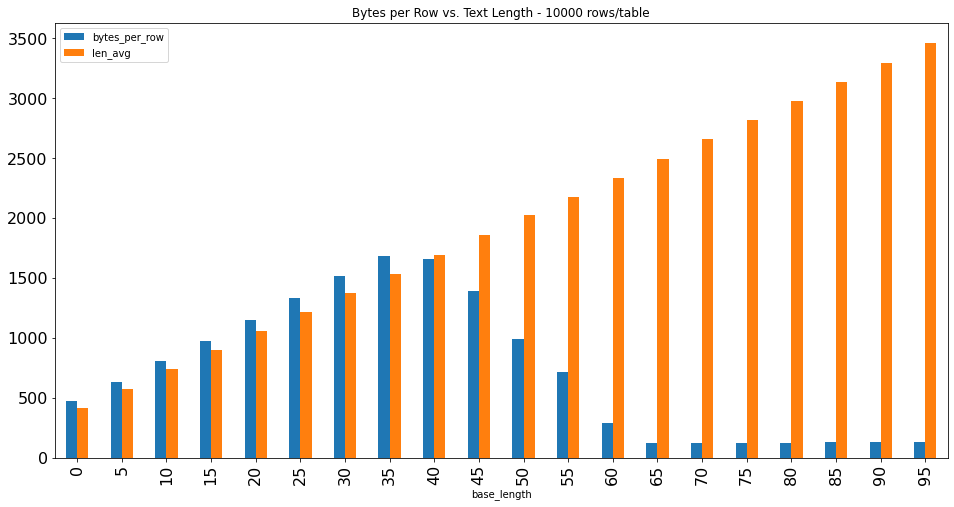
The following chart shows the results of string length versus
the total size on disk reported for each table, with
base lengths 0 through 95. Size on disk grows linearly with
the average string length up through base_length 35.
Between base_length 35 and 40, the largest records start being
compressed and the size on disk per row starts to decline.
By base_length of 65, all values are large enough for compression.
Note:
bytes_per_rowis collected from queries against our PgDD extension views. Thebytes_per_rowvalue is calculated using:pg_catalog.pg_table_size(pg_class.oid) / pg_class.reltuples
Using the results from the above chart, I was able to identify
a strategy for where I want to test further.
The following table displays details about a few base lengths below
and above the compression threshold.
At base_length=35 the generated strings have a range of lengths of
1152 - 1920 characters, keeping the largest values just under the 2kb threshold for compression.
Without compression, the reported bytes_per_row is a little
larger (around 9%) than len_avg for these lengths of text. This is expected.
Adjusting base_length=45 results in less than half of the
data exceeding the compression threshold, with a range of lengths of
1472 - 2240. This means some of our text values are being compressed,
while others are not. At this point the overall bytes_per_row is now lower than the len_avg by about 25%.
Adjusting base_length=65 results in all text values being compressed
with a range of lengths from 2112 - 2880, with only 120 bytes per
row... this size on disk is 95% lower than the length of the text!
| base_length | bytes_per_row | len_min | len_avg | len_max | |
|---|---|---|---|---|---|
| 0 | 0 | 468.5824 | 32 | 413.0560 | 800 |
| 2 | 10 | 808.5504 | 352 | 739.9104 | 1120 |
| 7 | 35 | 1679.3600 | 1152 | 1535.5616 | 1920 |
| 9 | 45 | 1386.9056 | 1472 | 1857.4144 | 2240 |
| 13 | 65 | 119.6032 | 2112 | 2495.7824 | 2880 |
Data ingestion testing
To get an idea of how Postgres handles performance bulk loading this
large-text data, big_text initiation scripts and tests were added
to our
pgbench-tests repo on GitHub.
Clone the repo on a test server under the postgres user.
sudo su - postgres
mkdir ~/git
cd ~/git
git clone https://github.com/rustprooflabs/pgbench-tests.git
cd pgbench-tests
See PostgreSQL performance on Raspberry Pi, Reporting edition for another use for the
pgbench-testsrepo.
Create a database for testing.
psql -c "DROP DATABASE IF EXISTS bench_test;"
psql -c "CREATE DATABASE bench_test;"
Initialize speed
To start testing bulk ingestion speed,
initialize the database with 1 million rows
(# of rows = scale * 10,000) using base_length=0 to start
getting an idea of how performance looks with smaller text sizes.
# Set variables for pgbench
export SCALE=100
export BASE_LENGTH=0
psql -d bench_test \
-v scale=$SCALE -v base_length=$BASE_LENGTH \
-f init/big_text.sql
Each test with timing provided was ran a minimum of three (3) times with the average time being reported.
Each test with timings was ran at least times
with a drop/create database between runs. Average times are provided.
With base_length=0, Postgres
consistently added 1M rows in around 8 seconds.
Setting base_length=35 (just below compression threshold)
increased the timing to about 19 seconds. At these base_length
values, the load timings were consistent.
At base_length=65 (100% compressed) there was considerable variation
between the slow and fast end of timings, ranging from 20 to 35 seconds.
This is an indicator the larger data ingestion is more sensitive
to performance variations. It also shows that the init script itself
is limited to single-threaded inserts due to how the query is written.
The following screenshot from htop shows how only 1 of 4 available
CPUs is being used.
Test INSERT speed
A better guide of INSERT performance with these large text values
(for my use case anyway) is to test
how well it handles the data coming in via one-off INSERTs.
Each step of testing drops and recreates the database and runs a fresh init. The only thing that changes for each repeated step is the
BASE_LENGTHvalue.export BASE_LENGTH=0 psql -c "DROP DATABASE IF EXISTS bench_test;" psql -c "CREATE DATABASE bench_test;" pgbench -c 20 -j 4 -T 600 -P 60 -n \ -D base_length=$BASE_LENGTH \ -f tests/big_text_insert.sql \ bench_test
Run the pgbench test for big text insert performance.
pgbench -c 20 -j 4 -T 600 -P 60 -n \
-D base_length=$BASE_LENGTH \
-f tests/big_text_insert.sql \
bench_test
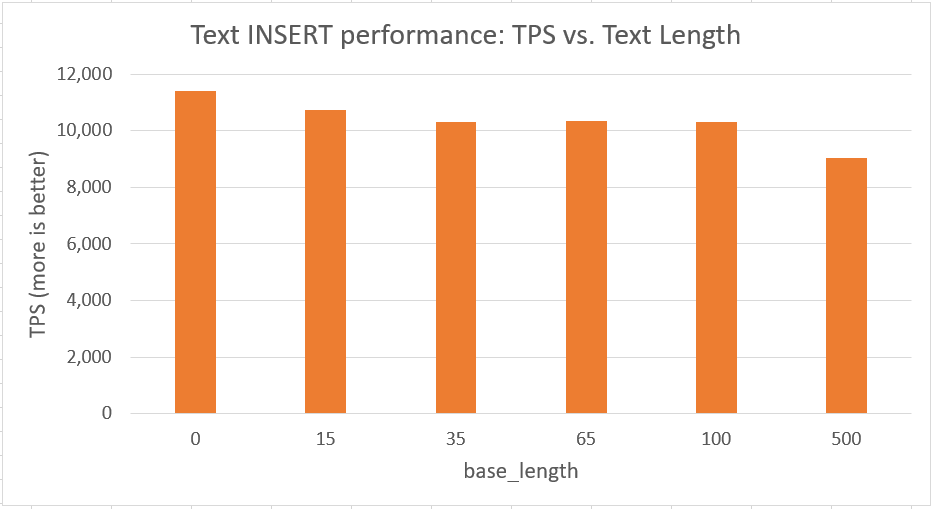
The pgbench output output shows this server can process
11,398 insert transactions per second (TPS) with relatively small text
(23 - 800 characters).
transaction type: tests/big_text_insert.sql
scaling factor: 1
query mode: simple
number of clients: 20
number of threads: 4
duration: 600 s
number of transactions actually processed: 6839292
latency average = 1.754 ms
latency stddev = 6.198 ms
tps = 11398.346050 (including connections establishing)
tps = 11398.425637 (excluding connections establishing)
As the size of text grows to base_length=35 (string lengths
1,152 - 1,920), the TPS drops to 10,322 (-9%). It holds steady
at that level of performance all the way up to base_length=100
(string length up to 4,032). By base_length=500 (string length up to 20,160) insert TPS has dropped to 9,024, -13% from lower levels.
EXTENDED vs. EXTERNAL
How does write performance compare to not using compression?
This can be tested by using the EXTERNAL storage method,
see the
TOAST page.
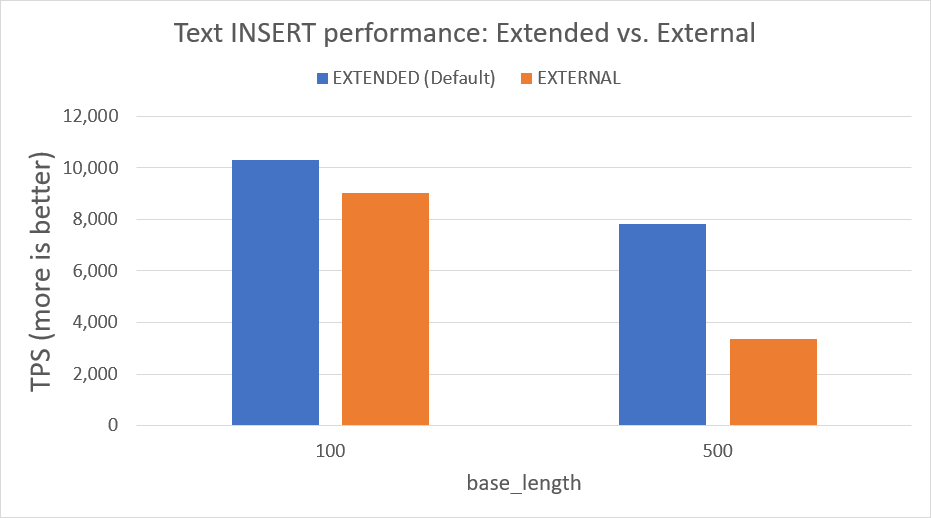
I tested the larger text sizes and this showed clear results:
compression on even a modestly-powered modern server is a good thing.
At base_length=100, using EXTERNAL is 24% slower. As the
size of text is increased to base_length=500, it is 63% slower
to bypass compression.
Size on Disk
Of course all the discussion about compression wouldn't be complete
without seeing how much compression we are getting.
At base_length=500, the compressed data (pgbench table) consumes 264 MB on disk.
The same data in EXTERNAL format (pgbench_ext) takes 16GB!
t_name |size_pretty|rows |bytes_per_row |
-----------|-----------|---------|-----------------|
pgbench |264 MB |1000044.0|276.5743267296239|
pgbench_ext|16 GB |1000000.0| 17164.763136|
Note: The actual compression ratio you get with your production data on your production system will likely be different than these exact results.
Read performance
The pgbench-tests repo
includes a few tests for SELECT performance with large text data.
There are tests there for both EXTENDED and EXTERNAL
storage methods and a few query examples, though I only discuss
one of the test queries here.
I was looking for any example that would show an advantage
for the EXTERNAL storage method. The documentation states
the advantage being on substring operations.
"Use of
EXTERNALwill make substring operations on wide text and bytea columns faster (at the penalty of increased storage space) because these operations are optimized to fetch only the required parts of the out-of-line value when it is not compressed." -- Postgres docs
I created a quick test for operating on a substring of the text
(EXTENDED
and
EXTERNAL).
In every scenario I tried, the default EXTENDED method
with compression was modestly to significantly faster than EXTERNAL. One example representative
of the overall trend was 3,300 TPS for EXTENDED but only 1,600 TPS
for EXTERNAL, 51% slower.
Summary
This post put the performance of PostgreSQL with large TEXT objects
to the test. I found the compression of text data cuts down on
the size on disk upwards of 98%.
Further, the performance of storing large text
objects holds up well as the size of text increases.
Finally, for the scenarios I am interested in,
disabling compression not only provides zero benefit,
it is detrimental to performance in nearly every way.
The default compression threshold at 2 kB seems decent, though I am curious if adjusting to a lower level (1 kB?) would be beneficial.
All-in all, it was a lot of fun working up the test cases and code to write this post!
Need help with your PostgreSQL servers or databases? Contact us to start the conversation!
 Mastodon
Mastodon