
Database Anti-patterns: Performance Killers
Databases are everywhere. They're in your computer, smartphone, WiFi enabled devices, and power all the web-driven technologies you use 24/7. Relational databases have the ability to provide incredible power, performance, reliance, and reporting. They also have the power to inflict severe pain, frustration, confusion and sleepless nights. You can expect the latter when a database is designed incorrectly.
This post attempts to summarize the most common, and most problematic relational database anti-patterns I have seen. These problems are not a technology problem; they are a training and experience problems. Some of these are mistakes I have made myself. Others I inherited in the form of a pre-existing system, and others still I was hired explicitly to fix.
Education is a Challenge
Relational database design, like cybersecurity, spans a wide range of very in-depth topics full of nuances and experience-driven decisions. In other words, there is a lot to learn and it isn't easy to teach. Another aspect of the problem is that database design isn't being taught very well, if at all, in typical database related coursework. Database courses focus on dry definitions of the various levels of normalization, yet spend zero effort teaching best practices for the design process or the decisions that go into determining the appropriate level of normalization.
Lots of theory, little application
Typical course work provides simple examples of creating tables, inserting and selecting data, and deleting tables. There is typically zero time spent discussing the realities of maintaining a production database with actual business requirements, up-time guarantees and the proper handling of sensitive data. Most notably, there is no discussion of the ethics of being the steward and gatekeeper for an organizations most important asset: it's data.
That last point is especially important for data professionals with the GDPR implementation almost here (May 2018).
Normalization and DML syntax is important to learn and understand, but it is such a tiny component of overall database design.
Side note: Database design process
Do yourself a favor and start on a whiteboard or paper. Seriously, don't write a single line of code, or even create the empty database, until you have invested some time sketching out tables, relationships, table names, basic columns, etc. Until then, you aren't ready to build a database. Even in Agile this should be considered part of "just enough design."
Most common anti-patterns
Below are the five (5) most common and problematic database anti-patterns I have dealt with in the past 10+ years. If you can learn to avoid these problems you're doing yourself and the world a favor.
Anti-Pattern One: Tables without PRIMARY KEY
I wish I was kidding when I say this, but once upon a time I found a database that had more than 200 tables without primary keys. None. Isn't the first thing taught in an Introductory SQL course that primary keys are a good thing?! If you read about relational databases on Wikipedia, the 4th sentance says (emphasis mine):
"This model organizes data into one or more tables (or "relations") of columns and rows, with a unique key identifying each row."
Ok, the casual reader may not understand that "a unique key identifying each row" is hinting at a primary key, but that's OK because only a handful of sentences later under the header "Keys" it says:
"Each row in a table has its own unique key."
... and ...
"Therefore, most physical implementations have a unique primary key (PK) for each table."
Got it. Tables should always have a unique primary key. Please make sure your tables have appropriate primary keys.
The problem of missing primary keys is almost always much bigger than just the PKs themselves. If there are no primary keys it's safe to assume that there are no foreign keys, unique constraints, or other helpful database constructs that help enforce data integrity and improve performance.
Anti-Pattern Two: CHAR(N) instead of VARCHAR(N)
In one database I found more than two dozen CHAR(12) columns that were storing variable length strings... yet CHAR(N) is only appropriate for fixed lenth strings. The average length of the data stored in those columns was only 7 characters, thus padding 5 bytes on average per value. (I go into further detail below under "Modeling data sizes") A second problem here was that expected values were (supposed to be) longer than 12 characters. Values with more than 12 characters were silently truncated. For example, the value "Flaminco guitar" would silently be cut off as "Flaminco gui". Hm, Flaminco GUI? Flaminco Graphical User Interface? That sure would make planying Flaminco Guitar easier!
Had those column been a sensible VARCHAR(50) everything would have been fine.
Silently truncating data quality errors is a sin of its own! Never do this.
Another side-effect was the padding stored in CHAR fields resulted in code like this scattered everywhere, though I'm still not sure why the LTRIM was necessary. My best guess is that it wasn't ever needed, the author of the code simply didn't know what was required so threw it in for a dose "Just in case".
SELECT RTRIM(LTRIM(<column_name>))
Modeling data sizes
In the instance referenced above, the average length of the data stored in a CHAR(12) field was 7 characters. In this scenario, a CHAR(12) column takes 12 bytes per row stored, regardless of the data in the column. A VARCHAR(50) column takes up one byte for every character (7) plus one (1) byte overhead per row stored: 7 + 1 = 8 bytes per row. The difference between a CHAR(12) and a VARCHAR(300) is the CHAR(12) takes an additional 4 bytes per row. That might not sound much right now, but that's 'is a 1/3 reduction in storage: (8 - 12) / 12 = -33%
Now imagine this table doesn't have just one column with this problem, but instead
has 30 columns like this. Further, there are 100 million rows of data.
This problem now balooned to waste more than 11 GB of space. In terms of raw storage space,
11 GB might not seem like that big of a deal.
The real issues caused by excessive data sizes come in when realities of limited disk I/O speed, available RAM,
and networking throughput all sink in.
Anti-Pattern Three: Extremely Wide Tables
Very few tables should have 196 columns. What's worse than 196 columns is when half of those columns didn't have any data at all in them. Further, another 25% of the columns duplicated data stored in lookup tables. Only 25% of the columns (less than 50) were useful and a dozen of those got split out into new tables because they didn't belong in the main table to begin with!
In general, tables typically shouldn't have more than 30 or 40 columns in them, with most tables having under 20 columns.
Anti-Pattern Four: Unnecessary DATETIME / TIMESTAMP
Like anti-pattern two above, using DATETIME everywhere when DATE is more appropriate should be avoided. Don't simply set it as DATETIME because you think you might need that detail sometime in the future. YAGNI. If the time component is not important now, do not waste the space. Again, it is a 4-byte difference per value, and those values can add up quickly.
Anti-Pattern Five: Never deleting anything
This problem isn't typically one that affects performance, but it does negatively impact readability and understandability of the code. I've literally reduced the code in a database by 50-75% throughout, by simply deleting commented out code that should have been deleted years ago.
Commented Out Code
I've found examples like this far too often. What we have here are dozens of lines of SQL code with a bunch commented out and the rest actually needed.
Note: Every linestarting with -- is a "comment" in SQL and is not executed.
SELECT column1, column2,
-- This used to be used back in the dark ages, so I just commented it out now that we stopped using it eons ago.
-- insert
-- dozens
-- of
-- lines
-- of
-- old
-- code
-- here.
FROM dbo.table1
-- Ignore this next line...
-- INNER JOIN dbo.table_we_no_longer_use ....
The solution for this is to use source control, like Git. Source control tracks all of your changes, so if you need to find one-off code from a few years ago, you can find it. Without that one-off code getting in the way the other 99.9% of the time.
Backup Table Graveyard
I despise finding a dozen tables like this.
SELECT *
FROM user_table_backup_2008_March;
Obviously this was a point in time snapshot of a specific table many years ago. Why is it still here? The problem with tables like this is it indicates that there isn't a mature backup/restore process in place to rely on in case something goes wrong. You (or your DBA) should have a reliable, scheduled backups that they can use to restore the data if the worst does happen.
Plus, "backup" tables like this example break any referential integrity there was on the original base table.
Anti-Pattern Six (Bonus!): Views referencing Views referencing views.....
A view in a relational database is essentially a saved query. Views are often used to perform calculations on the fly, hide nasty joins, or rename columns. Views are an important part of most databases. In general, most views should reference database tables with proper indexes.
What you really don't want to do is have more than two or three layers of nested views, where one view references another view that references a third view. Even that 3rd layer should be unnecessary for most properly designed databases.
Deep nested views can be bad for a number of reasons. The complexity of these views grows out of control. Trying to analyze these views for performance (either humans or the query planner) is a losing battle. This makes it hard for humans to maintain, and hard for the query planner to determine the most efficient queries.
Exceptions are if you're using materialized views in PostgreSQL or Indexed Views in MS SQL Server.
Note: MS SQL Server indexed views cannot use other views as their source, though they can be used to speed up complex base queries themselves.
When is it OK to Break the Rules?
As with most rules or best practices, there are times when it is ok to bend or break them as there is no one-size-fits-all database solution.
Staging Tables
Staging tables are tables that store data temporarily during an import or ETL (Extract, Transform, Load) process. Staging tables are allowed to break anti-patterns 1, 3 and 4. Source data frequently does not have a primary key, or the records contain duplication. Source data is often wider than what a typical relational table stores and may include full timestamps even when not necessary.
The loosly defined staging tables accept the dirty data with the assumption that the load process sanitizes the data while loading to production.
Reporting / Data warehouse
My definition of wide tables (anti-pattern 3) changes when a database is primarily focused on reporting or analytical queries. Though, even in a data warehouse scenario, I still would argue against the design of any tables exceeding 50-75 columns and suggest possible split points where multiple tables may be more appropriate.
Short Term Use
I'm guilty of creating a copy of a table as a temporary backup before running an UPDATE statment I'm a bit nervous about. This would typically be done in a test environment when I'm writing the tricky update syntax. In this case, the consequence of a bad statement might mean having to reload the full test database. If that process could take more than 10 minutes, creating a fail-safe for myself for testing purposes is OK.
Please don't litter production databases with this nonsense. You or your DBA should have a reliable and tested backup/restore process for your databases.
So what's the big deal?
At this point you might be wondering why these anti-patterns are such big problems in my eyes. A lot of little mistakes made over time combine to have serious ramifications. An experienced mountain climber once told me that you don't ignore the little mistakes, because you could be one little mistake away from falling to your doom. Databases typically are intended to live long lives in comparison to the rest of our software and systems. Small mistakes build up a residue over time and can make your database feel its age sooner than expected.
The point is, having one column set as a CHAR(15) instead of a VARCHAR(15) (probably) won't kill its performance. Similarly, one table with 56 columns isn't a deal breaker. The real problem comes up when you have a repetitive pattern of these anti-patterns throughout an entire large database. The following screenshot came from a database I was performance tuning because it had gound to a painful halt. Even basic queries returning a few thousand rows were taking minutes (sometimes dozens of minutes) to execute and return results. Note the data size going through the query node I was examining, a whopping 57GB!
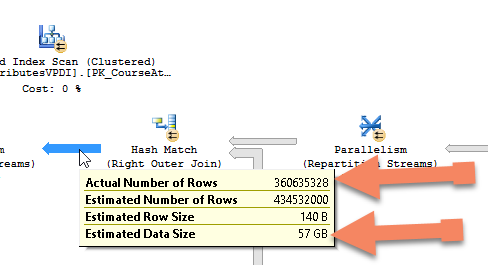
When I saw this result I couldn't believe it. It seemed impossible because the entire database was only 32 GB yet that one step in this view was moving 57 GB around! I double and triple checked the stats, and it was happening. No wonder it was slow!
The view that produced that screenshot suffered from all of the anti-patterns I described above. Considering that SQL Server runs on dedicated hardware, has many cores, and RAM in the 100s of GB, a small- to medium-sized database should not be able to brint it to its knees and speaks of how poorly the database was designed. That's painfully true if you compare that to the performance I was able to pull from PostgreSQL on a Raspberry Pi 2B+.
The little mistakes add up.
Anti-pattern Overview
Now for a handy summary of what to avoid to avoid these anti-patterns:
- AP1: Missing PK indicates wide-spread problems. Good luck.
- AP2: Wrong data type
- AP3: Too many columns
- AP4: Wrong data type
- AP5: Dead weight everywhere
- AP6: Super-views have big egos
Parting thoughts
I have made all these mistakes myself in various projects. There's a database I built more than five years ago that still lives on despite the multitude of mistakes and oversights I made in my initial designs. It wasn't long after I made those exact mistakes that I wrote this post! One by one I'm righting my previous mistakes, but refactoring a database of that scale isn't easy either.
I will end this post with the same challenge I gave to myself in 2013.
Set aside dedicated time every week to do something that will likely lead to a mistake I can learn from.
 Mastodon
Mastodon