
Use BIGINT in Postgres
This post examines a common database design decision
involving the choice of using BIGINT versus INT data types.
You may already know that the BIGINT data type uses
twice the storage on disk (8 bytes per value) compared to
the INT data type (4 bytes per value).
Knowing this, a common
decision is to use INT wherever possible, only resorting to using
BIGINT when it was obvious*
that the column will be storing
values greater than 2.147 Billion (the
max of INT).
That's what I did too, until 2-3 years ago!
I started changing my default mindset to using BIGINT over INT,
reversing my long-held habit.
This post explains why I default to using BIGINT
and examine the performance impacts of the decision.
TLDR;
As I conclude at the end:
The tests I ran here show that a production-scale database with properly sized hardware can handle that slight overhead with no problem.
Why default to BIGINT?
The main reason to default to BIGINT is to avoid
INT to BIGINT migrations. The need to do an INT
to BIGINT migration comes up at the
least opportune time and the task is time consuming.
This type of migration typically involves at least one column used
as a PRIMARY KEY and that is often used elsewhere as a FOREIGN KEY
on other table(s) that must also be migrated.
In the spirit of defensive database design, BIGINT
is the safest choice. Remember the *obvious part mentioned
above? Planning and estimating is a difficult topic and
people (myself included) get it wrong all the time!
Yes, there is overhead for using BIGINT,
but I believe the overhead associated with the extra 4 bytes
is trivial for the majority of production databases.
If you have a production database in 2021 I will assume:
- Fast SSDs
- Enough RAM
- Enough CPU
Setup to Test
The tests in this post used a Digital Ocean droplet with 8 AMD CPU and 16 GB RAM. Ubuntu 20.04 and Postgres 13.
I performed additional testing using a server with half the power and another with twice the power. The data scale was adjusted accordingly and similar results were observed in each set of tests.
I created two databases,
one for INT and one for BIGINT. The names of the
databases help track which results went with which test,
and database names show up in the commands via htop and iotop.
CREATE DATABASE testint;
CREATE DATABASE testbigint;
Setup the pgbench structure with --scale=100
in the testint database. Using 100 for the scale results
in 10 million rows in the largest table (pgbench_accounts).
pgbench -i -s 100 testint
...
done in 14.31 s (drop tables 0.00 s, create tables 0.00 s, client-side generate 9.48 s, vacuum 1.74 s, primary keys 3.09 s).
14 seconds, not too shabby. The pgbench tables use int4
so this database is ready for testing performance of the
INT data type.
Now use pgbench to prepare the testbigint database with
the same scale.
pgbench -i -s 100 testbigint
The testbigint needs to have the INT columns converted
to BIGINT for testing. I used the dd.columns
view from the PgDD extension
to build the queries needed to alter all int4 (INT)
columns to the int8 (BIGINT) data type.
SELECT 'ALTER TABLE ' || s_name || '.' || t_name || ' ALTER COLUMN ' || column_name || ' TYPE BIGINT;'
FROM dd.columns
WHERE s_name = 'public'
AND t_name LIKE 'pgbench%'
AND data_type = 'int4'
;
The above query returns the following ALTER TABLE commands.
ALTER TABLE public.pgbench_accounts ALTER COLUMN aid TYPE BIGINT;
ALTER TABLE public.pgbench_accounts ALTER COLUMN bid TYPE BIGINT;
ALTER TABLE public.pgbench_accounts ALTER COLUMN abalance TYPE BIGINT;
ALTER TABLE public.pgbench_branches ALTER COLUMN bid TYPE BIGINT;
ALTER TABLE public.pgbench_branches ALTER COLUMN bbalance TYPE BIGINT;
ALTER TABLE public.pgbench_history ALTER COLUMN tid TYPE BIGINT;
ALTER TABLE public.pgbench_history ALTER COLUMN bid TYPE BIGINT;
ALTER TABLE public.pgbench_history ALTER COLUMN aid TYPE BIGINT;
ALTER TABLE public.pgbench_history ALTER COLUMN delta TYPE BIGINT;
ALTER TABLE public.pgbench_tellers ALTER COLUMN tid TYPE BIGINT;
ALTER TABLE public.pgbench_tellers ALTER COLUMN bid TYPE BIGINT;
ALTER TABLE public.pgbench_tellers ALTER COLUMN tbalance TYPE BIGINT;
The ALTER TABLE queries were saved into a .sql file to
make it easy to run with an overall timing.
nano pgbench_int_to_bigint.sql
The ALTER TABLE queries took 1 minute 8 seconds.
This means it took 54 seconds longer to change the data type
than it took to create the entire database from pgbench
to begin with!
time psql -d testbigint -f pgbench_int_to_bigint.sql
real 1m7.863s
user 0m0.032s
sys 0m0.013s
The biggest table here only has 10 million rows. The wait times get longer as the data grows toward 2 billion rows!
At this point I did a VACUUM ANALYZE against both databases and rebooted
the instance.
Simple performance checks
I picked an account number (aid) and tested this
query against both databases.
EXPLAIN (ANALYZE)
SELECT *
FROM public.pgbench_accounts
WHERE aid = 9582132
;
The important part of the output was the timing (in ms), shown in the following table. Re-running the query on either database returns results in the 0.040 - 0.100 ms range with no clear winner between the two. The query plans (not shown) were identical including estimated costs.
| Query | Data type | Execution time (ms) |
|---|---|---|
| Simple Select | INT | 0.040 |
| Simple Select | BIGINT | 0.044 |
The following query is a more complex query to hopefully
highlight the differences a bit more.
The filter (WHERE bid = 1) uses a sequence scan on one
INT/BIGINT column while applying multiple aggregates to
the abalance column, another INT/BIGINT columns.
This query shows a slight performance
edge for INT over BIGINT in the range of 2% to 3%.
While there is a minor difference in performance, the timing
difference is less than 20 ms, hardly a major concern for a query
that takes half a second.
EXPLAIN (ANALYZE, COSTS OFF)
SELECT COUNT(*) AS accounts,
MIN(abalance), AVG(abalance)::FLOAT8, MAX(abalance), SUM(abalance)
FROM public.pgbench_accounts
WHERE bid = 1
;
| Query | Data type | Execution time (ms) |
|---|---|---|
| Seq Scan and Aggs | INT | 514 |
| Seq Scan and Aggs | BIGINT | 527 |
Indexes are more important
A quick tangent on indexes. The pgbench init scripts do not index
the pgbench_accounts.bid column.
The above query that filtered on bid and aggregated the balances
illustrates that a proper indexing strategy will have a far larger
impact on performance then the choice of INT or BIGINT data types!
Taking a look at the aggregate query in pgMustard's query plan tool highlights the missing index.
The plan from the BIGINT query
reports a sequence scan taking 460 ms (on 3 threads even!), 92% of the
entire execution time of 500 ms!
pgMustard correctly suggests adding an index to the bid
column with a 5 star rating for the suggestion.
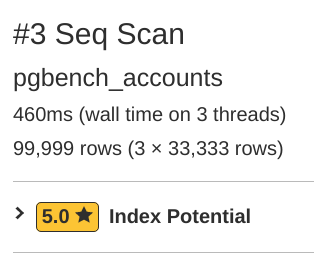
I added the index.
CREATE INDEX ix_pgbench_accounts_bid
ON public.pgbench_accounts (bid);
The query on BIGINT now runs in only 35 ms by using the index!
Here's the plan on pgMustard.
With a proper index in place the performance difference between INT
and BIGINT becomes trivial.
Larger scale tests
The above tests took a look at performance at the individual query
level.
This section uses pgbench to put the database under a heavier
load of queries.
The first pgbench command used against each database
is intended to put the server under pressure but not push it
to the breaking point. It uses the --select-only option
to skip the insert/update queries.
pgbench -c 5 -j 1 -T 600 -P 60 --select-only <db_name>
This 10 minute test (-T 600 is in seconds)
against the testint database ran
25.0 M transactions with a latency average of 0.113 ms.
The latency average reported by pgbench is the time it
took to execute the query and return results.
number of transactions actually processed: 25009788
latency average = 0.113 ms
latency stddev = 0.039 ms
tps = 41682.966689 (including connections establishing)
tps = 41683.153363 (excluding connections establishing)
Against the testbigint database, pgbench processed 25.3 M transactions!
That means the BIGINT test ran slightly faster, not slower! 🤔
The latency average was 0.112 ms.
number of transactions actually processed: 25273848
latency average = 0.112 ms
latency stddev = 0.033 ms
tps = 42123.068142 (including connections establishing)
tps = 42123.222043 (excluding connections establishing)
I re-ran these tests a few times (like I do for all tests) and achieved consistent results. My hunch is that this unexpected result is a side effect of my quick test methods.
Even larger tests
The last set of tests put the databases under a heavy load for the given size of hardware. This set of tests looks at what happens under a stressful load condition. These tests break my earlier assumption about the database having "enough CPU."
The following pgbench commands bump the connection count up from
5 up to 20. The first command uses the default pgbench
tests that include a mix of read/write queries. The
second uses the --select-only used above.
pgbench -c 20 -j 4 -T 600 -P 60 <db_name>
pgbench -c 20 -j 4 -T 600 -P 60 --select-only <db_name>
Under this heavier load the difference between INT and BIGINT
becomes more noticeable.
The TCP (like) tests showed BIGINT handled 8% fewer
Transactions Per Second (TPS) than the INT database.
The Select Only queries showed BIGINT handled 6%
fewer TPS.
| Bench test | INT TPS | BIGINT TPS | % Diff |
|---|---|---|---|
| Read/Write | 7,538 | 6,959 | -7.7% |
| Select Only | 64,489 | 60,437 | -6.2% |
The load simulated in this section is too high to expect a server of this size to gracefully handle. It is interesting that it takes your server being under serious stress in order to see a noticeable drop in performance from using
BIGINTinstead ofINT.
While the read/write test was running against the testint
database I took the following screenshot from htop.
The screenshot was taken at the 5-minute mark of the 10-minute test and
shows that this server is struggling to keep up with the queries.
If your database server is working this hard, you should be
working on a plan to up-size your hardware!
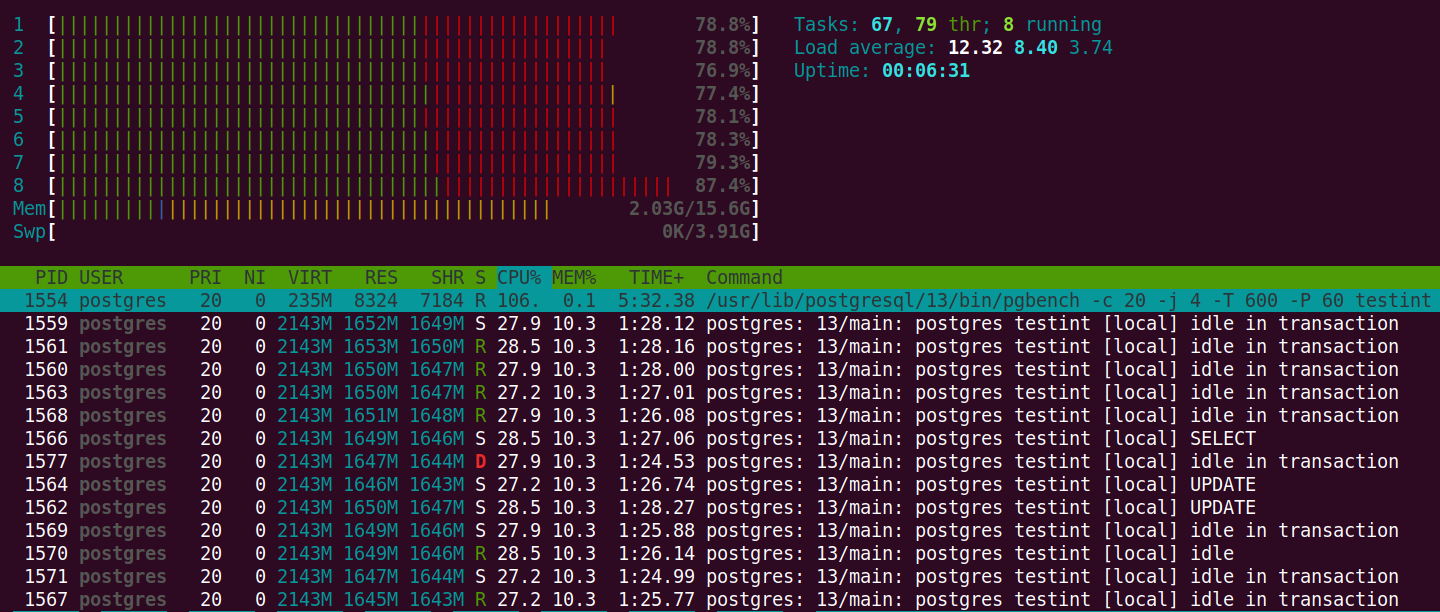
Not using BIGINT
There are still valid reasons to prefer avoiding BIGINT
unless absolutely necessary.
Do not take this generalized advice as a reason to list
very specific, non-standard use cases that benefits from the lowest
possible overhead. You're preaching to the choir... I know!
I love running Postgres on a Raspberry Pi
and have embraced the occasional headache that comes up from time
to time.
Here's an incomplete list of some cases where using INT over BIGINT
might still be a good default.
- Tables that store limited lookup options (e.g. Yes/No/Maybe)
- Low power, embedded sensing, Raspberry Pi
- Restrictions from limited network bandwidth
- Stubbornness
I list stubbornness in all seriousness. After all, my posts from 2014 on using a seriously undersized server to host Jira are still visited on a regular basis! These were my most popular posts up until about 2018 or so. (Weird, right?) I had stubbornly gotten Jira to work, spent a massive amount of time fighting it, and I gained a ton of experience you can only learn the hard way. As I wrote, my stubbornness has caused me pain:
"After the fourth hard crash (remember, I'm stubborn)..."
The popularity of those posts makes it seem like I'm not the only
one... Maybe you want to set yourself
up for an unexpected INT to BIGINT migration.
Summary
This post covered why I will continue using BIGINT as
the default over INT. Ultimately, I'm choosing to adopt a slight
overhead across the board in order to avoid having
to repeatedly go through INT to BIGINT migrations. The tests
I ran here show that a production-scale database with properly
sized hardware can handle that slight overhead with no problem.
Only when the server becomes severely loaded do those slight differences
in overhead translate into noticeably slower query times or throughput.
Need help with your PostgreSQL servers or databases? Contact us to start the conversation!
 Mastodon
Mastodon