
Use PostgreSQL file_fdw to Access External Data
Loading external data is a core task for many database administrators. With Postgres we have the powerful option of using Foreign Data Wrappers (FDW) to bring in external data sources. FDWs allow us to access data that is external to the database by using SQL from within the database. These external data sources can be in a number of formats, including other relational databases (Postgres, Oracle, MySQL), NoSQL sources (MongoDB, Redis), raw data files (csv, JSON) and many more.
This post shows how to use
file_fdw
to load remote data from CSV files available from GitHub. Sharing data
via public source control tools like GitHub has become a common way
to make data sets widely available. Other public data is available
from various government and non-profit sites, so this is a handy tool to have available and reuse.
External data source
For this post I am using the
COVID-19 data John Hopkins University is curating. See
the main GitHub page for full attribution
and meta-details about the data.
The specific files I want to load are under ./csse_covid_19_data/csse_covid_19_daily_reports,
with one file per date and each file containing the latest details by region. The format of the
CSV file has changed at least twice since January, and the level of detail has become more
granular as the virus has spread and more data has been collected.
The current file format started on 3/21/2020 and includes data with the following structure. Below is the first record from the 3/26/2020 file. The U.S. data goes down to the county level and includes a latitude/longitude that can be fed into PostGIS for mapping purposes.
┌─[ RECORD 1 ]───┬──────────────────────────────────────────────┐
│ fips │ 45001 │
│ admin2 │ Abbeville │
│ province_state │ South Carolina │
│ country_region │ US │
│ last_update │ 2020-03-26 23:48:35-06 │
│ lat │ 34.22333378 │
│ lon │ -82.46170658 │
│ confirmed │ 3 │
│ deaths │ 0 │
│ recovered │ 0 │
│ active │ 0 │
│ combined_key │ Abbeville, South Carolina, US │
Perpare file_fdw
FDWs are enabled by creating the appropriate extension in the database you need it in.
For accessing data in files we use file_fdw.
CREATE EXTENSION file_fdw;
Next, create the SERVER to
use, every FOREIGN TABLE requires a server.
The command for file_fdw is relatively simple, no connection parameters are needed in this case.
CREATE SERVER fdw_files FOREIGN DATA WRAPPER file_fdw;
The following SQL creates the foreign table to connect to the raw CSV file on GitHub. The first line uses
CREATE FOREIGN TABLE, adding the FOREIGN keyword in the middle of the standard sytnax.
The main declaration of the table itself is like any standard table, name the columns
how we like and provide data types matching the source file. The line with
SERVER fdw_files OPTIONS is where the magic begins.
Using the program option, we can use a wget command to stream
the CSV data directly from GitHub (or any URL returning data!) into Postgres.
CREATE FOREIGN TABLE public.covid_staging
(
fips TEXT,
admin2 TEXT,
province_state TEXT,
country_region TEXT,
last_update TIMESTAMPTZ,
lat FLOAT,
lon FLOAT,
confirmed INT,
deaths INT,
recovered INT,
active INT,
combined_key TEXT
)
SERVER fdw_files OPTIONS
(
program 'wget -q -O - "https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_daily_reports/03-26-2020.csv"',
format 'csv',
header 'true'
);
Verify the table was created and includes data with a quick COUNT(*) query.
([local] 🐘) postgres@covid=# SELECT COUNT(*) FROM public.covid_staging;
┌─[ RECORD 1 ]─┐
│ count │ 3421 │
└───────┴──────┘
Neat! The remote CSV data is now available. What next?
Persist the data
When loading remote data I normally want to persist the data internally. This JHU data source has a new
file for every date of data, so I will create a standard table and load each day's data into that as needed.
This is a good time to take advantage of a new feature in Postgres 12,
generated columns.
I use this to provide a way geometry column converted from the included longitude (x) / latitude (y) values.
CREATE SCHEMA covid19;
CREATE TABLE covid19.daily
(
id BIGINT NOT NULL GENERATED BY DEFAULT AS IDENTITY,
fips TEXT NULL,
admin2 TEXT NULL,
province_state TEXT NULL,
country_region TEXT NOT NULL,
last_update TIMESTAMPTZ NOT NULL,
lat FLOAT NULL,
lon FLOAT NULL,
confirmed INT,
deaths INT,
recovered INT,
active INT,
combined_key TEXT,
source_date DATE,
way GEOMETRY(POINT, 3857)
GENERATED ALWAYS AS ( ST_Transform(ST_SetSRID(ST_Point(lon, lat), 4326), 3857 )) STORED ,
CONSTRAINT pk_covid_daily_id PRIMARY KEY (id)
);
Create a spatial index on the generated geometry column.
CREATE INDEX gix_covid_daily ON covid19.daily
USING GIST (way);
COMMENT ON TABLE covid19.daily IS 'COVID-19 daily data loaded from John Hopkins University GitHub repo. See https://github.com/CSSEGISandData/COVID-19';
COMMENT ON COLUMN covid19.daily.source_date IS 'Date used in filename of remote file. e.g. https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_daily_reports/03-26-2020.csv';
Now an INSERT query will load the data from the foreign staging table.
INSERT INTO covid19.daily (fips, admin2, province_state, country_region, last_update,
lat, lon, confirmed, deaths, recovered, source_date)
SELECT fips, admin2, province_state, country_region, last_update,
lat, lon, confirmed, deaths, recovered, '2020-03-26'::DATE
FROM public.covid_staging;
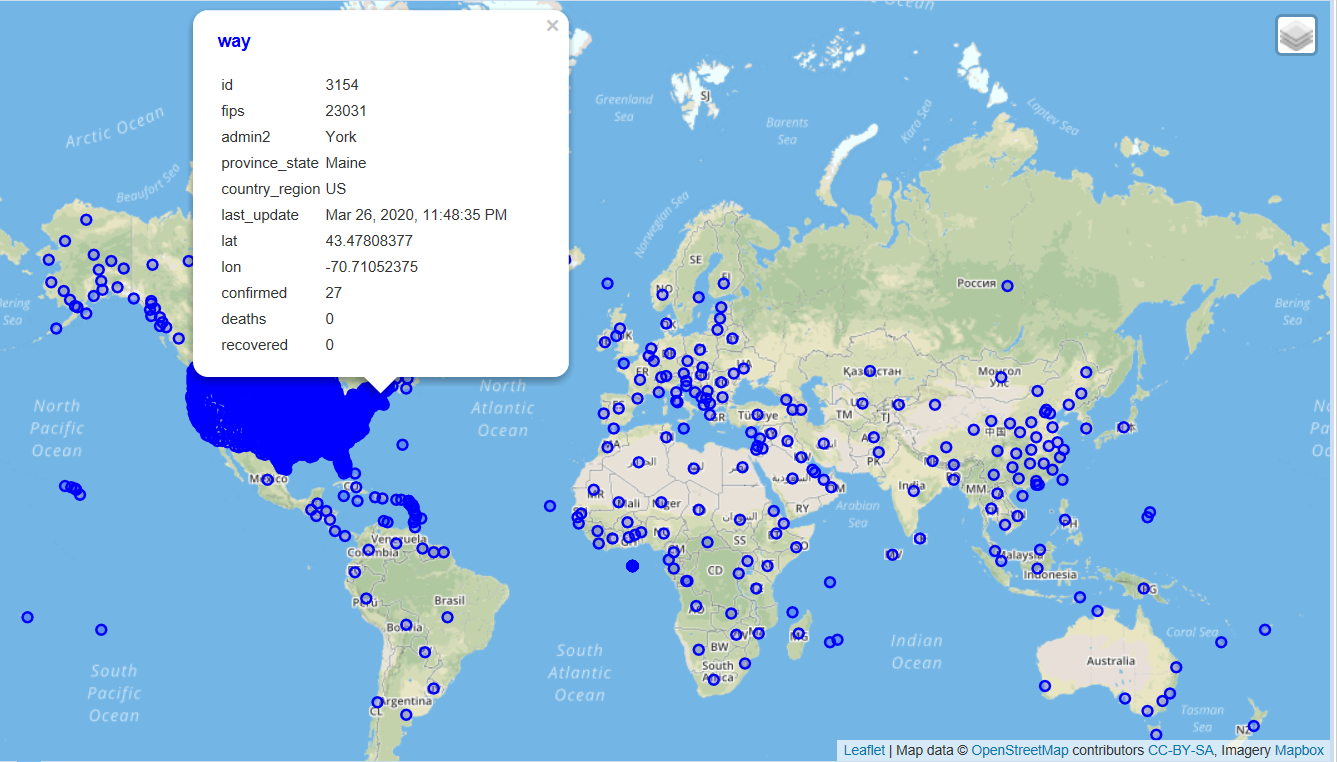
With the data loaded to this table it is easy to start visualizing the results in DBeaver. The first thing that is apparent is the data inside the U.S. is available at a relatively granular level and the data outside is mostly by country. The popup dialog is displaying the values from a single point I clicked on within Maine.
Rinse and Repeat
With the remote data for one day loaded permanently to Postgres, use DROP FOREIGN TABLE public.covid_staging; to
remove the foreign table. The foreign table can be quickly recreated linking to a new file for a new date
and run the INSERT again to continue loading to the covid19.daily table.
Summary
This post has walked through how to use file_fdw to link Postgres to a remote file and load it into
a database table. This is a powerful and handy tool for integrating and managing data from a huge number
of public data sources.
Need help with your PostgreSQL servers or databases? Contact us to start the conversation!
 Mastodon
Mastodon