
SQL for Institutional Research (IR)
One of the questions I see frequently from Institutional Research (IR) professionals are exploratory ones about getting started with SQL. They typically have a good background and understanding of how to work with data, but they just haven't made the leap to using a relational database. Data may be stored in CSV or Excel format (flat file style) and loaded into a statistical analysis package (such as SPSS, SAS, Stata, or even R) for analysis work. Over time, the desire for multi-year trend analysis leads to stacking files from multiple source files, which we all know gets unwieldy very fast.
This post attempts to outline some key elements for learning when starting down the road to adding a proper relational database into your data work flow. Practical code examples are given with small snippets throughout. If you're not ready to learn the code yet, feel free to skim over those examples.
I have also tried to provide external links to other great resources throughout, especially where there are differences between database platforms. So read on!
What this Post Is Not
This post does not try to teach best practices for the sake of simplicity. It's really an attempt at a "crash course" to help point you in the right direction. This post assumes that you are not responsible for maintaining the database other than loading and querying data. This assumes someone else (IT?) will install and manage the server, apply patches and upgrades, and be responsible for taking backups and ensuring the backups can be restored.
This post also does not attempt to provide a comprehensive review of the multitude of database platforms available. The examples I've given should work in most versions of the most popular database platforms, such as MS SQL Server, PostgreSQL, MySQL and so on. My examples were written and tested on PostgreSQL 9.3.
If you have any questions or troubles with the examples given, please let me know using our Contact form!
Connecting to the Database
Before you can take advantage of your database, you need to know how to connect to it. The tools for this vary based on your database platform. If you're using MS SQL Server, check out SQL Server Management Studio (SSMS). PostgreSQL users should give PgAdminIII a shot. MySQL users tend to use PHPMyAdmin or MySQL Workbench.
No matter the platform, your IT department should be able to help advise you on how to connect to the database, including user name and other credentials.
Retrieving Data
The next task is to start querying data. For now I will assume that a database is already created with two tables: student and course. Jumping right in, let's see what data is
currently in the student table, using a basic SELECT command.
SELECT * FROM student;
Results in something like this (PgAdminIII):

There are GUI query builders, but I highly suggest learning the basic SQL commands to really take advantage of the power of the database!
Parts of a Query
The query above (SELECT * FROM student;) is about as simple as it gets. It isn't an
example of best practices, but it's perfect for quickly exploring the data available,
telling the database to show us everything.
The SELECT statement is fairly straightforward, and is one of the four
DML commands.
The Asterix * tells the database to return all columns available.
FROM student; tells the database what table to retrieve records from. Notice the
trailing semi-colon (;)... while not required necessarily by all databases,
it is defined in the ANSI SQL-92 standard as the proper delimiter between SQL statements.
Joining Tables
The power of relational databases comes from the ability to join related data together! I know, I know... I was surprised too.
The next example builds off our last query to bring in the courses from the course table
for each student.
I am now specifying exactly the columns I want, you'll notice I'm now defining each
column instead of using the simple *. Unless you're exploring data, it's best to
explicitly define the desired columns.
SELECT s.id, s.name_first, s.name_last, c.term, c.prefix, c.num, c.grade
FROM student s
INNER JOIN course c ON s.id = c.student_id;
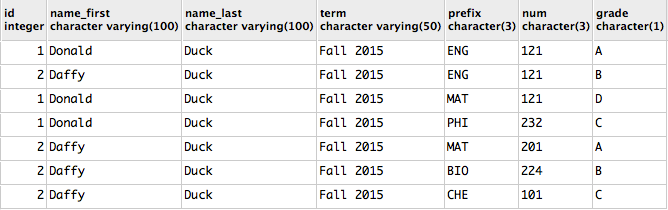
I have also added an INNER JOIN statement to define the relationship between
the id column in the student table with the student_id column in the course table.
Check out this post on Coding Horror for a visual explanation of SQL joins.
Common Aliases Used
In the example above, the student table now has an alias of s, so by defining
s.id I am telling the database to pull the id column from student table.
I find it's best to use aliases that still represent their source to make maintenance
as easy as possible.
Sometimes I do use generic a, b, c for quick throw-away scripts, but anything that might
haunt me in the future I try to make as explicit as possible.
Specifically related to IR data, I typically think of some basic data elements.
- applicant =
a - course =
c - demographic =
d - graduate =
g
.... and so on. When I use calendar tables, I use cal as the alias because when
I see c, I immediately think course data!
Limiting Results
When working with large tables it's best to limit the number of results returned to save on server resources, network bandwidth and other such things. If you don't be nice to the server, IT may be knocking on your door...
This task uses database dependent syntax. PostgreSQL and MySQL both use a LIMIT 10
format, but their exact syntax does differ slightly.
MS SQL Server uses TOP 10.
Creating Tables
Fast forward, and now you want to add graduation data on your students. This means
you need to create a new table to store the data. Let's create the grad table.
CREATE TABLE grad
(
id SERIAL PRIMARY KEY,
student_id INT NOT NULL,
grad_date DATE NOT NULL,
degree VARCHAR(200)
);
Auto-Incrementing columns are database specific.
PostgreSQL uses
SERIAL,
MS SQL usesIDENTITYand MySQL uses AUTO_INCREMENT
Loading Data
Loading data presents a number of challenges, and there are a number of ways to approach it.
For starters, we'll just use simple INSERT queries.
Inserting one row is easy:
INSERT INTO grad (student_id, grad_date, degree)
VALUES
(1, '2015-12-15', 'Performing Arts');
Inserting multiple rows isn't really any more difficult, just watch your commas.
INSERT INTO grad (student_id, grad_date, degree)
VALUES
(2, '2015-12-15', 'Performing Arts'),
(1, '2015-12-15', 'Basket Weaving');
Now with a new element of data to look at we can quickly count the number of
students earning each degree and calculate the average age by degree on the on the date of graduation.
This query now requires the use of GROUP BY because we're using aggregates (COUNT and AVG). I've also opted to ORDER BY the degree as well.
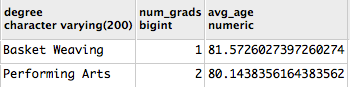
SELECT g.degree,
COUNT(s.id) AS num_grads,
AVG(g.grad_date - s.dob)/365 AS avg_age
FROM grad g
INNER JOIN student s ON g.student_id = s.id
GROUP BY g.degree
ORDER BY g.degree;
"Quick Concat" statement
While writing INSERT statements isn't all that tricky, it isn't very efficient either
if you're writing them by hand. Suppose you had a few thousand rows of data in Excel
and want to load it into your shiny new database. This is a quick and dirty method of
accomplishing the task, but it comes with the happy effect of being relatively easy to implement.
The next example is a formula that can be pasted into Excel to load data from columns A through D. The tricky part with these formulas is getting the single and double quotes setup properly.
Here's the formula:
=CONCATENATE("INSERT student VALUES ('",A2,"','",B2,"','",C2,"','",TEXT(D2,"yyyy-mm-dd"),"', '",E2,"');")
I created a few more student records in Excel that I want to load in to the database. In the formula bar of the screenshot you can see the formula pasted in, and in column F you can see the INSERT statements generated, ready to copy and paste into our database.

Kim Wallace, Director of Institutional Research at Front Range Community College, showed me this trick years ago, and I have yet to find a better way to quickly load some random data into SQL.
Dates can become a quick headache, pay attention to
TEXT(D2,"yyyy-mm-dd")in the formula above!
Data Loading Resources
To go further into the topic of data loading gets into too many "It Depends" scenarios. It all depends on what format your data comes in, what database platform you choose, and what other software you already use. Below are some resources to look into for a few of the major systems you may use or be interested in.
Most major database platforms have a way to load data quickly. These built-in data loading methods will probably be the highest performing option, but also typically requires some method of getting the data file loaded to a hard drive on the database server itself.
MS Access has the ability to link to source files and to tables in a database. Using this method you can build out user friendly forms and maybe even add in a sprinkle of VBA to really polish it up.
Last, most statistical analysis packages should have the ability to connect to various RDMSs, but I've always found that to be a clunky solution. I only have experience here with SPSS -> MS SQL and the major downside is that SPSS loads records RBAR (Row By Agonizing Row), and therefore isn't very fast at all.
Test for Yourself
Nothing beats getting hands on experience. So what to do next?
Technically Savvy
If you're technically inclined and aren't intimidated by setting up your own VPS, check out Amazon's AWS Free Tier, just be mindful of your usage limits. If you can stay within the boundaries you'll get a full year free (at time of writing, anyway!). Go there, spool up an instance in EC2, and have at it!
Non-Technical
If you aren't inclined to setup your own database server (which is the target audience for this post!), please get in touch with me using the form on our Contact page. Let me know what your situation is, what sort of database setup you're looking to test, and I'll do my best to get you on the right path.
 Mastodon
Mastodon